
Wordlists, frequency lists, vocabularies
Lexical Computing is a supplier of word frequency data and other lexical databases for IT applications.
Wordlist — frequency lists and linguistic databases
The wordlist tool generates frequency lists of various kinds:
- nouns, verbs, adjectives and other parts of speech
- words beginning, ending, containing certain characters
- word forms, tags, lemmas and other attributes
or a combination of the three options above.
Three different frequency measures can be displayed in the wordlist: frequency, frequency per million and ARF.
How to use the wordlist
Visit the related Quick start guide or watch this video.
Hover the mouse over icons, controls and other elements to display the tooltips. Click the highlighted words to learn about the functions and settings.
How does the wordlist work?
The wordlist works on the token level. The default settings will produce a list of words because non-words are excluded automatically.
The wordlist can also be limited by frequency by setting the minimum and maximum limit.
Frequencies can be obtained for a list of concrete words. Use the from this list: option on the advanced tab and input the items for which frequencies should be calculated from the selected corpus.
Regular expressions can be used to define complex criteria for the words that should be included in the frequency list.
Including more information in the result
The Display as option allows including more attributes into the result. For example, a frequency list of word forms can be generated with lemmas displayed alongside the word forms. Up to 3 attributes are allowed.
Limitation
When the Display as option is used, first a concordance of all tokens matching the criteria is generated and the frequencies are computed from the concordance. The size of this concordance have a technical limitation of 10 million concordance lines. As a result, if the corpus is very large, the frequency data may not be computed from the whole corpus.
Speed and corpus size
Sketch Engine is specifically designed to handle large corpora with speed. Any search will only take a few seconds two to complete if the corpus size is under a billion words. It might take a bit of extra time for corpora over 1 billion words. Complex regular expressions criteria used on large corpora might require a several-minute wait.
Requirements for word list to work well
The only requirement is a tokenized corpus. The results will be more representative if the list is generated from a large corpus. There is, however, no minimum corpus size required for the wordlist to work.
Speed, corpus size, limitations
Sketch Engine is specifically designed to handle large corpora with speed. Any search will only take a few seconds two to complete if the corpus size is under a billion words. It might take a bit of extra time for corpora over 1 billion words. Complex criteria set with regular expressions on large corpora can take several minutes to complete.
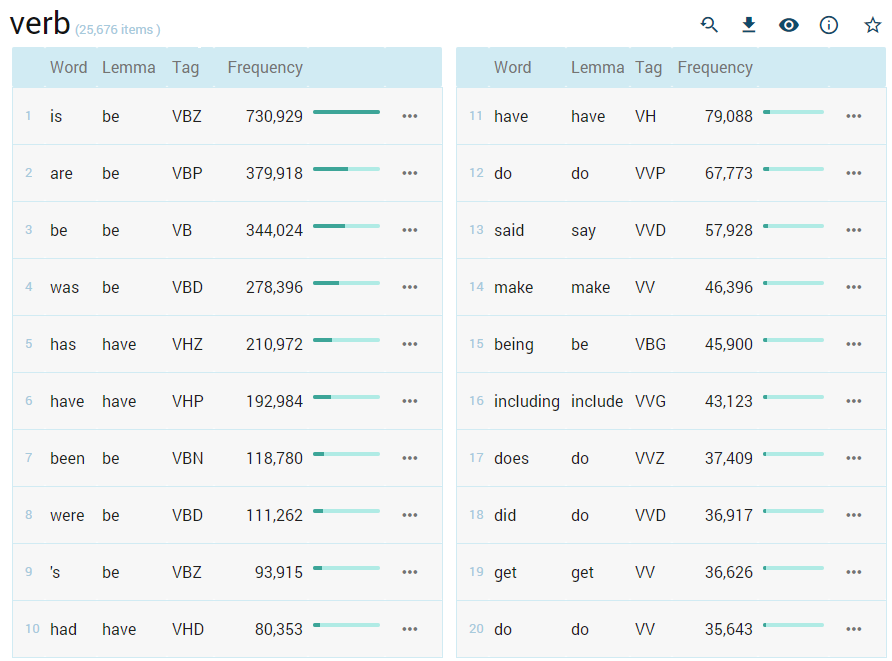
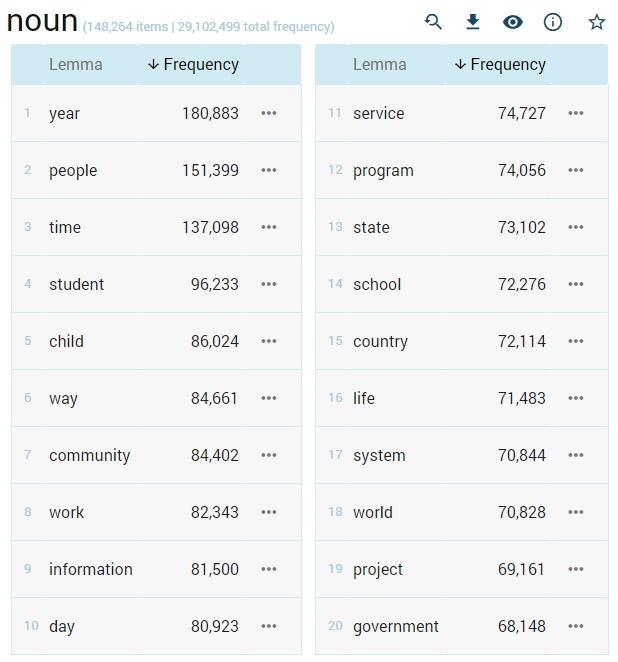
Result examples
A simple list of nouns with the most frequent noun at the top.
A list of word forms of nouns with the most frequent word form at the top accompanied by lemmas and part-of-speech tags.
