POS tags
POS tag (disambiguation)
This page is about the POS tag (usually called ‘tag’), the full morphological tag with information about the part of speech and also number, gender, case, tense and other grammatical categories. The POS tag is not the POS attribute, which contains only the part-of-speech information. More on the POS attribute.
This blog post defines what POS tags are, explains manual and automatic POS tagging and points readers to Sketch Engine where they can have their texts tagged automatically in many languages.
What is a POS tag?
A POS tag (or part-of-speech tag) is a label assigned to each token (word) in a text corpus to indicate the part of speech and often also other grammatical categories such as tense, number (plural/singular), case etc. POS tags are used in corpus searches and in text analysis tools and algorithms.
POS tagset
A set of all POS tags used in a corpus is called a tagset. Tagsets for different languages are typically different. They can be completely different for unrelated languages and very similar for similar languages, but this is not always the rule. Tagsets can also go to a different level of detail. Basic tagsets may only include tags for the most common parts of speech (N for noun, V for verb, A for adjective etc.). It is, however, more common to go into more detail and distinguish between nouns in singular and plural, verbal conjugations, tenses, aspect, voice and much more. Individual researchers might even develop their own very specialized tagsets to accommodate their research needs.
How can I…?
POS-tag my data
Upload your data/text into Sketch Engine to pos-tag and lemmatize them automatically. Then download the processed data.
use my own POS tags
Data can be annotated manually to introduce specific tags or attributes or data annotated automatically can be post-edited.
see some tagsets
All tagsets used in Sketch Engine are published online.

A concordance from Sketch Engine with POS tags displayed.
What are POS tags used for?
POS tags make it possible for automatic text processing tools to take into account which part of speech each word is. This facilitates the use of linguistic criteria in addition to statistics.
For languages where the same word can have different parts of speech, e.g. work in English, POS tags are used to distinguish between the occurrences of the word when used as a noun or verb.
POS tags are also used to search for examples of grammatical or lexical patterns without specifying a concrete word, e.g. to find examples of any plural noun not preceded by an article.
Or both of the above can be combined, e.g. find the word help used as a noun followed by any verb in the past tense.

POS tagging
POS tagging is often also referred to as annotation or POS annotation.
Manual annotation
Annotation by human annotators is rarely used nowadays because it is an extremely laborious process. For best results, more than one annotator is needed and attention must be paid to annotator agreement. This is often facilitated by the use of a specialized annotation software which does not assign POS tags but checks for any inconsistencies between annotators. When the software identifies a word (token) with different POS tags from each annotator, the annotators must find a resolution on how to annotate the word or might decide to expand the tagset to accommodate the new situation.
Nowadays, manual annotation is typically used to annotate a small corpus to be used as training data for the development of a new automatic POS tagger. Annotating modern multi-billion-word corpora manually is unrealistic and automatic tagging is used instead.
Automatic POS annotation
Due to the size of modern corpora, the only viable tagging option is an automatic annotation. The tool that does the tagging is called a POS tagger, or simply a tagger. It can work with a high level of accuracy reaching up to 98 % and the mistakes are typically only limited to phenomena of less interest such as misspelt words, rare usage or interjections (e.g. yuppeeee might be tagged incorrectly). Ambiguity also poses a problem. In the sentence Time flies., it is difficult to tell if it is made up of noun + verb or verb + noun. The latter meaning Use a stopwatch to measure (the movement of) insects. :-) Despite certain inaccuracies, modern tools are able to annotate a vast majority of the corpus correctly and the mistakes they make hardly ever cause problems when using the corpus.
During the development of an automatic POS tagger, a small sample (at least 1 million words) of manually annotated training data is needed. The tagger uses it to “learn” how the language should be tagged. It works also with the context of the word in order to assign the most appropriate POS tag. Automatic taggers can only be as good as the quality of the training data. If the training data contain errors or inconsistencies originating from low annotator agreement, data annotated by such taggers will also reflect these problems.
Taggers for each language can be mutually unrelated tools and each one can use different approaches, algorithms, programming languages and configurations. Apart from those, there are also tools which can be trained to process more than one language. The core software stays the same, but a different language model is used for each language.
How to POS tag your data?
DIY approach – open source POS taggers
Many POS taggers are available for download on the internet and are often open source. Their use may, however, require adequate (often high-level) technical skill of installing and configuring them.
Ready-made POS tagging solutions
The easiest way to tag your data for parts of speech is to use a ready-made solution such as uploading your texts to Sketch Engine, which already contains POS taggers for many languages. Any text the user uploads are tagged (and often also lemmatized) automatically. No technical knowledge or IT skills are required to have the data tagged. The tagged data can be analysed and searched in Sketch Engine or downloaded for use with other tools.
 https://www.sketchengine.eu/wp-content/uploads/topic-classification-ententen20.png
532
1065
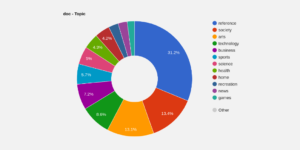
2024-02-21 16:01:022024-02-22 08:44:05Topics and genres in corpora
https://www.sketchengine.eu/wp-content/uploads/topic-classification-ententen20.png
532
1065
2024-02-21 16:01:022024-02-22 08:44:05Topics and genres in corpora https://www.sketchengine.eu/wp-content/uploads/lowercase.png
301
392
2020-01-06 16:16:592020-07-02 11:31:20Case sensitive and insensitive corpus analysis
https://www.sketchengine.eu/wp-content/uploads/lowercase.png
301
392
2020-01-06 16:16:592020-07-02 11:31:20Case sensitive and insensitive corpus analysis https://www.sketchengine.eu/wp-content/uploads/lemma-tag-lempos.png
301
392
2019-10-30 09:54:502020-04-07 15:21:00Words, tags, lemmas, lemposes, lowercase
https://www.sketchengine.eu/wp-content/uploads/lemma-tag-lempos.png
301
392
2019-10-30 09:54:502020-04-07 15:21:00Words, tags, lemmas, lemposes, lowercase https://www.sketchengine.eu/wp-content/uploads/corpus-from-web-blog2.png
307
400
2019-05-13 15:12:372026-05-29 14:18:49Build a corpus from the web
https://www.sketchengine.eu/wp-content/uploads/corpus-from-web-blog2.png
307
400
2019-05-13 15:12:372026-05-29 14:18:49Build a corpus from the web https://www.sketchengine.eu/wp-content/uploads/post-tags.png
301
392
2018-03-27 18:13:392026-05-11 09:29:32POS tags
https://www.sketchengine.eu/wp-content/uploads/post-tags.png
301
392
2018-03-27 18:13:392026-05-11 09:29:32POS tags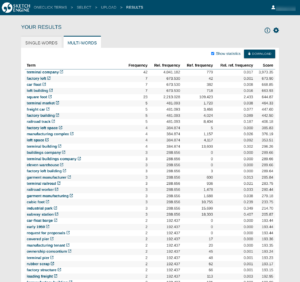 https://www.sketchengine.eu/wp-content/uploads/multi-word-terms-wikipedia-automotive-industry.png
1203
1280
2018-01-16 17:34:142024-10-15 11:42:41The best term extraction
https://www.sketchengine.eu/wp-content/uploads/multi-word-terms-wikipedia-automotive-industry.png
1203
1280
2018-01-16 17:34:142024-10-15 11:42:41The best term extraction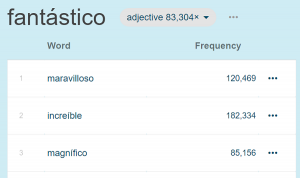 https://www.sketchengine.eu/wp-content/uploads/blog_th_fantastico.png
355
600
2017-11-29 12:02:182021-01-07 15:00:12Automatic thesaurus
https://www.sketchengine.eu/wp-content/uploads/blog_th_fantastico.png
355
600
2017-11-29 12:02:182021-01-07 15:00:12Automatic thesaurus https://www.sketchengine.eu/wp-content/uploads/2017-10-19_9-50-18.png
506
1169
2017-10-19 10:46:432020-12-02 18:03:45Corpus annotation and structures
https://www.sketchengine.eu/wp-content/uploads/2017-10-19_9-50-18.png
506
1169
2017-10-19 10:46:432020-12-02 18:03:45Corpus annotation and structures https://www.sketchengine.eu/wp-content/uploads/blog_ws_weather.png
407
600
2017-08-21 19:51:502026-04-01 13:57:57Most frequent or most typical collocations?
https://www.sketchengine.eu/wp-content/uploads/blog_ws_weather.png
407
600
2017-08-21 19:51:502026-04-01 13:57:57Most frequent or most typical collocations?

