Find X (word sketch highlights) enriches the word sketch feature by providing additional information about the word usage. The Find X function displays information about the usage of words, e.g. whether
- a word is rather used in the plural or the singular
- a word usually occurs in spoken language or written language
- a verb appears more in the present participle (-ing form) than in passive or vice versa, etc.
The Find X function can be used in the British National Corpus. Here are the words for which the word sketch highlights will be displayed, e.g.:
- noun people is usually used in the plural
- verb police is usually used in the present participle (the –ing form of a verb)
- verb associate is usually used in the past participle (also called passive)
- noun mummy is usually used in spoken language
How to use the Find X function?

Word sketch
The word sketch feature provides a one-page summary of a word’s grammatical and collocational behavior.
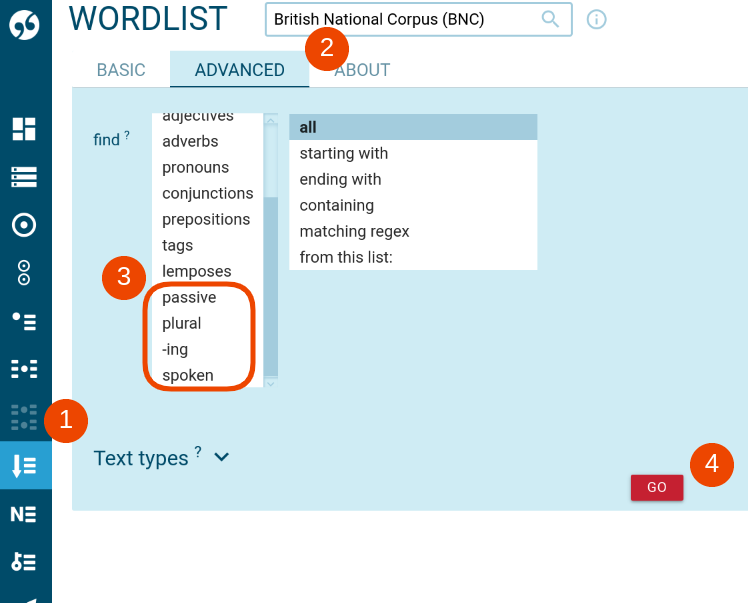
Find X word highlights results via Word list
Users can list all words of the particular word highlights definition via the Advanced tab of the word list feature.
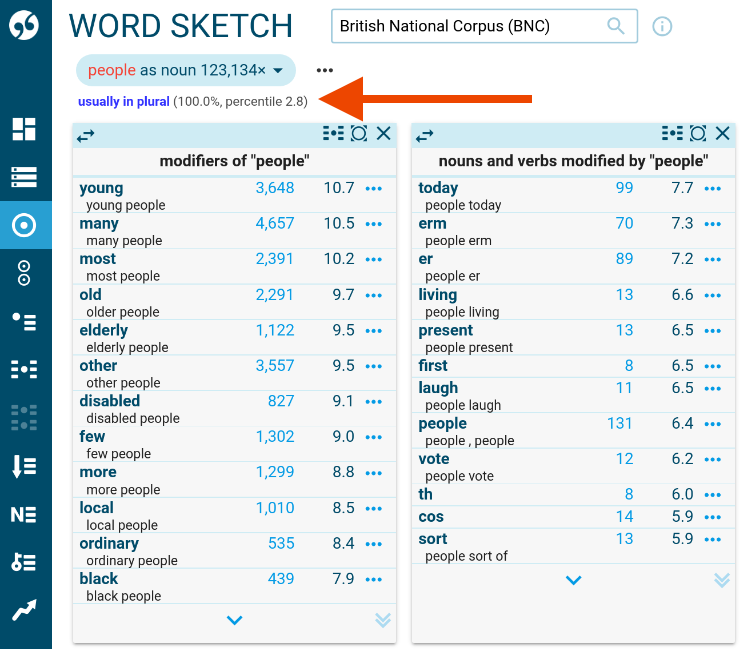
Find X word highlights in Word sketch
If the word corresponds to the definition of a word highlight and matches the criteria, this information is displayed above the standard word sketch results.
How to create a definition file for word highlights?
Three types of definitions
Word highlights can be defined in three ways.
1) a specified CQL query:
- (Q1) In this scenario, the frequency of the pattern specified by the CQL, with the word substituted at %s in Q1, is divided by the frequency of the word.
freq(Q1[word]) / freq(word)
2) a comparison of two such CQL queries:
- (Q1 and Q2) In this scenario, the frequency of the Q1 query (with the word instantiated at %s) is divided by the sum of that same frequency and the frequency of Q2 (with the word instantiated at %s).
freq(Q1[word]) / (freq(Q1[word]) + freq(Q2[word]))
3) a word sketch definition:
- (WS) Here the frequency of the word in the word sketch grammatical relation is divided by the frequency of the word in the entire corpus.
-
freq(WS[word]) / freq(word)
Brief documentation
Q1 – CQL query (mandatory or S1 for parts of corpora)
Q2 – CQL query (optional)
S1 – part of corpus or subcorpus (mandatory or Q1 for queries)
S1 – part of corpus or subcorpus (optional)
HR – human-readable name (optional)
RE – regular expression, e.g. n$ when use lempos attribute in Q1(optional)
TH – threshold (depending on the type of definition)
CL – coloring the information, e.g. red or blue (optional)
WS – word sketch definition name, e.g. usage patterns (mandatory if used)
Definition file format
Find X (word sketch highlights) definition file format
=highlight_id HR human readable name Q1 query_1 Q2 query_2 # optional RE regular_expression # optional
or
=highlight_id HR human readable name WS wsdef_relation_name RE regular_expression # optional
# All strings in the definition files starting with # are comments and are ignored to the end of the line.
Examples of the definitions
Examples
searching passive forms using the lempos attribute
=passive
HR verbs that are most often passive
Q1 [lempos=="%s" & tag="VBB_T"]
RE -v$
searching plural forms using the lempos attribute
=plural
HR nouns that are most often plural
Q1 [lempos=="%s" & tag="NNS_."]
RE -n$
searching with using threshold and colors
=spoken
S1 spoken
TH 50
RE -[nvj]$
CL rgb(50, 50, 100)
“spoken” should be replaced with the name of subcorpus (spaces are replaced with underscores)
Bibliographical reference
Adam Kilgarriff and Pavel Rychlý (2008). Finding the words which are most X. In Proceedings of the 13th EURALEX International Congress. Spain, July 2008, pp. 433–436
