comparable corpusA comparable corpus is a corpus consisting of texts from the same domain in more languages. In contrast to a parallel corpus, the texts are not translations of each other and belong to the same domain with the same metadata. An example of a comparable corpus is corpus made from Wikipedia.
learner corpusA collection of texts produced by learners of a language used to study errors and mistakes made by learners of languages. Learner corpora in Sketch Engine can use both error and correction annotation. A special search interface is available to search by the former or the latter or both.
see [...] Read More
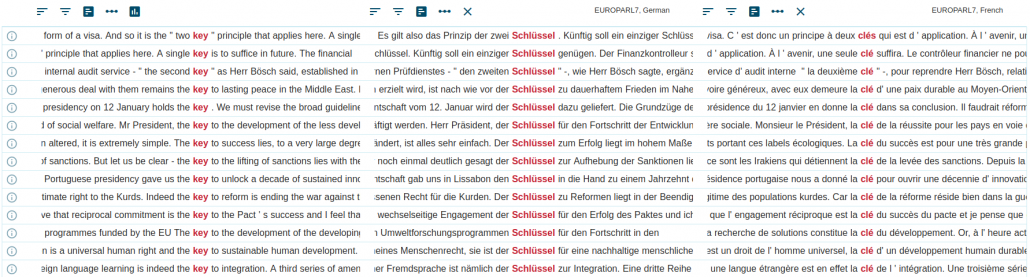
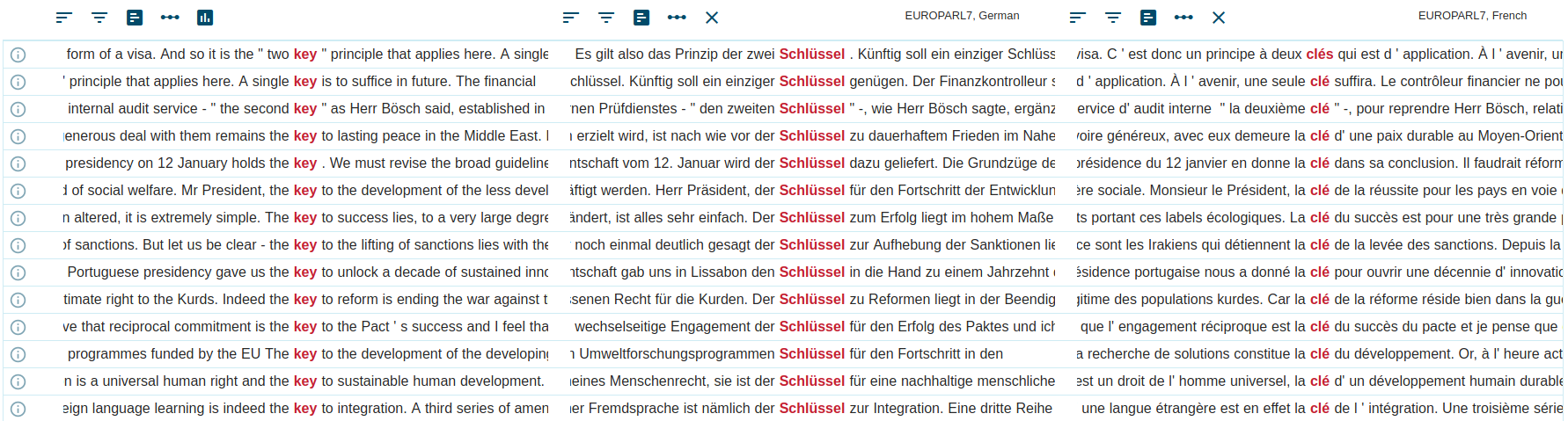
parallel corpusA parallel corpus consists of the same text translated into one or more languages. The texts are aligned (matching segments, usual sentences, are linked). The corpus allows searches in one or both languages to look up or compare translations.
user corpusa corpus created by a user. Users can create corpora by uploading their own data or using Sketch Engine to collect data from the Web. User corpora are created as private. No other user can access them.
However, users can grant access to the corpus to individually selected users. This is [...] Read More