- ALDF – Average Logarithmic Distance Frequencyis a modified frequency that prevents the result from being excessively influenced by one part of the corpus (e.g. one or more documents) that contain a high concentration of the token. If the token is evenly distributed across the corpus, ALDF and absolute frequency will be similar or [...] Read More
- alignmentAlignment is a term used in connection with parallel corpora. A parallel corpus consists of a text and its translation into one or more languages. Parallel corpora need to be divided into segments. A segment usually corresponds to a sentence. Alignment refers to information that tells Sketch [...] Read More
- ARF – Average Reduced Frequencya modified frequency which prevents the result to be excessively influenced by one part of the corpus (e.g. one or more documents) which contains a high concentration of the token. If the token is evenly distributed across the corpus, ARF and absolute frequency will be similar or identical. [...] Read More
- AttributeAn attribute can refer to:
Positional attribute
A positional attribute - information added to each token in a corpus, e.g. its lemma or part of speech. In this example, the token has three positional attributes: the word form doing, the part-of-speech tag VERB and the lemma doword tag [...]
Read More - CAT toolA CAT tool is a computer-assisted translation tool. It is software that helps translators maintain consistency in terminology across their translation projects and also aids the translation process by suggesting (or automatically translating) passages (segments) that have already been [...] Read More
- clusterClustering is the process of creating groups of words in the thesaurus or word sketch. Words are connected by their shared collocational behaviour. See more on the Clustering Neighbours documentation
- collocateis the part of a collocation that is not the node. A collocate is dependent on the node.
The collocate strong and the node wind make up the collocation strong wind
The most typical [...] Read Morecollocation collocate node strong wind icy wind cold wind - collocationA collocation is a sequence or combination of words that occur together more often than would be expected by chance (from Wikipedia|Collocation) A collocation, e.g. fatal error, typically consists of a node (error) and a collocate (fatal). !--more--The words in a collocation may appear [...] Read More
- comparable corpusA comparable corpus is a corpus consisting of texts from the same domain in more languages. In contrast to a parallel corpus, the texts are not translations of each other and belong to the same domain with the same metadata. An example of a comparable corpus is corpus made from Wikipedia.
- compileA corpus compilation refers to the processing of the corpus data (text) with the tools in Sketch Engine to prepare the data for searching and analysis.
Here is a list of some actions that happen during compilation:
- word sketches are precalculated
- thesarus is precalculated [...]
. ^ $ * + ? ( ) [ ] { } | \
In CQL, also the double quotes " must be [...] Read MoreFormula
number of hits : corpus size in millions of tokens = [...] Read MoreA statistics measure similar to logDice which is the minimum of the two following numbers:
- the number of co-occurrences divided by the frequency of the collocate
- the number of co-occurrences divided by the frequency of the node word
The minimum sensitivity number grows with a [...]
Read More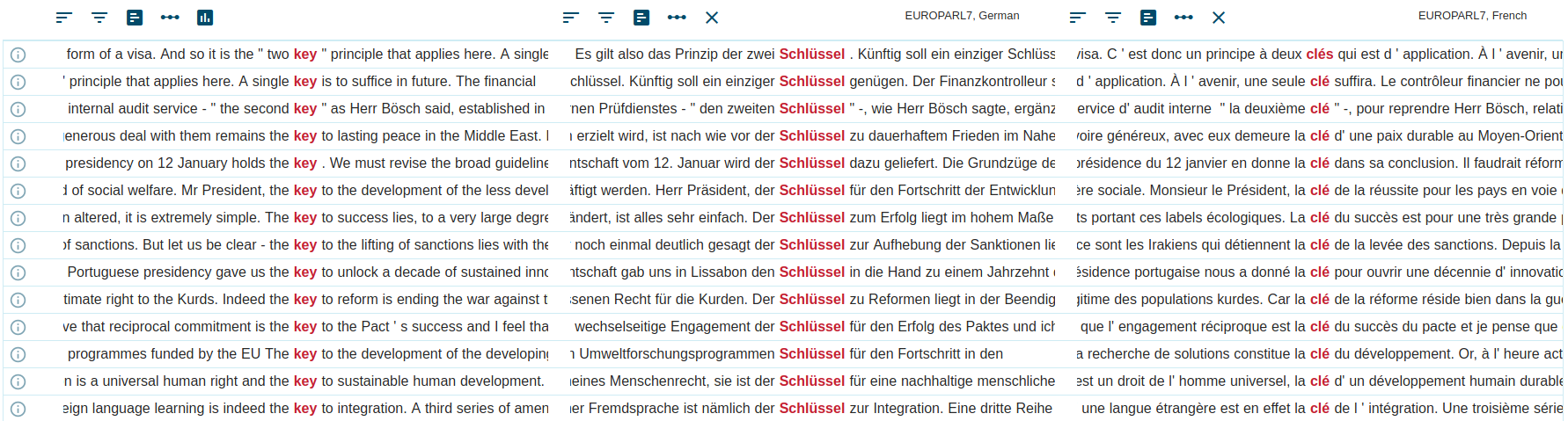
- It is used generally to refer noun, verb, adjective etc.
- POS can also refer to the POS attribute which is explained below.
| word | lemma | tag |
- a word form: going, trees, Mary, twenty-five…
- punctuation: comma, dot, question mark, quotes…
- digit: 50,000…
- abbreviations*, product names: 3M, i600, XP, e.g., etc., FB …
- anything else between [...]
