
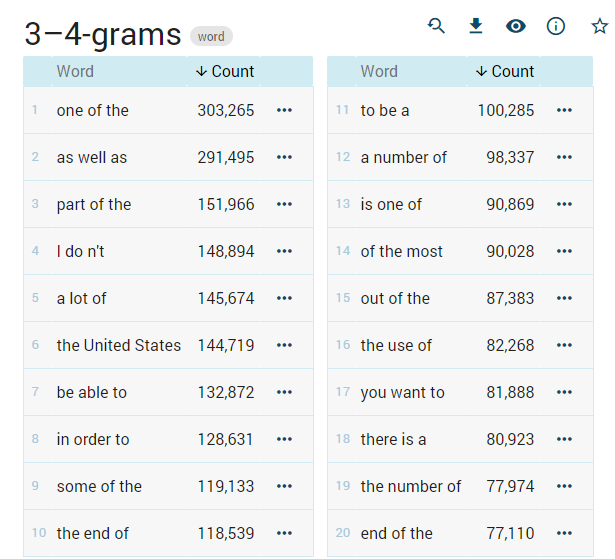
N-grams — frequency lists of multiword expressions (MWEs) or lexical bundles
The n-gram tool produces frequency lists of sequences of tokens. N-grams are also called multi-word expressions (or MWEs) or lexical bundles. The user has a choice of filtering options including regular expressions to specify in detail which n-grams should have their frequency generated. N-grams can be generated on any attribute with word and lemma being the most frequently used ones.
How to use n-grams
Hover the mouse over icons, controls and other elements to display the tooltips. Click the highlighted words to learn bout the functions and settings.
How do n-grams work?
N-grams are composed of tokens, this is why don’t like is a trigram and will be displayed as do n’t like. (In a concordance, don’t will be displayed without a space but also treated as two tokens.)
The result can be limited by minimum and maximum frequency. By default, low-frequency n-grams are excluded. Use the advanced tab to change this.
Regular expressions can be used to define complex criteria for the n-grams that should be included in the frequency list. When using regular expressions, the whole n-gram is treated as one continuous sequence of characters which also includes spaces.
There are two versions of the starting, ending and containing filters. One for filtering by characters (letters) appearing anywhere inside an n-gram and one for filtering by complete words, i.e. what is found between two spaces.
Limitation
When generating n-grams from very large corpora, only the first 1 billion tokens from the corpus are used for generating the n-gram list. If the corpus is larger, the rest of the corpus will not be reflected. This is a technical limitation which cannot be overcome. An n-gram list generated from the whole corpus can be produced at a fee. Contact Sketch Engine.
Requirements for the n-grams to work well
N-grams will work with any corpus as long as it is tokenized. Lemma or tag n-grams will only be available for lemmatized and tagged corpora. Tokenization, lemmatization and tagging are carried out automatically upon uploading files to Sketch Engine provided the language is supported.
Speed and corpus size
Sketch Engine is designed specifically to handle very large corpora with speed. Generating an n-gram list is a matter of a second or two. Wordlists from large multi-billion-word corpora can take several seconds to complete. The use of very complex regular expressions may slow the process down considerably.
