Most frequent or most typical collocations – which is more useful?
Word sketches in Sketch Engine are one-page summaries of word combinations (called collocations) that typically occurd with a word prefers. These summaries are computed automatically based on a language sample of billions of words called a text corpus.
By looking at the page, the users get an instant idea of how the word is typically used, the contexts in which it appears most frequently and what its typical word combinations are. The user can also go directly to the source sentences from which the information was extracted to check the context in detail.
An example of a word sketch might look like this:

The combinations are divided into categories such as modifiers, verbs, objects or subjects of a verb etc.
Apparently, each word can form more word combinations than those displayed in a word sketch by default. So how does Sketch Engine determine which collocations should be displayed? Where is the cut-off point? Users generally assume that this happens on the basis of frequency and that the collocations at the top of the list are the most frequent collocations. This would be, in most cases, not very useful as we will see further below. Sketch Engine takes a different approach and focuses on the typicality (or strength of collocation) rather than on frequency of use.
What is the difference between frequency and typicality?
Frequency (weak collocations)
Surprisingly, the fact that a word combination is frequent is often of limited use or even insignificant in terms of language teaching/learning or language research. For example, here are the most frequent collocations of the word bedroom (only adjectives modifying the noun are included)
own
spare
front
main
big
large
Looking at the list, we can see that most of the words are very predictable. In other words, if a student of English wants to speak about a bedroom of a small size, they will naturally use the word small. They will not usually need to consult a dictionary to make sure that small is a suitable word combination. Similarly, when teaching bedroom as a new word, it is not useful to point students to collocations such as small, own, big or comfortable because they are quite predictable. The collocations in this list would be classified as weak collocations.
Typicality (strong collocations)
On the other hand, typicality is used with collocations that are useful for learning, teaching or inclusion in dictionaries. Typicality focuses on collocations that are not (completely) predictable. An example of such a collocation from the list above is twin bedroom. A collocation list for bedroom ordered by typicality score will look quite different with these items at the top:
double
spacious
en-suite
upstairs
guest
air-conditioned
This list is more useful for language learning and more interesting for linguists and lexicographers. It all depends on the language level, of course, and the first list might be actually useful to beginners but it is the second list that we would expect to see when we want to learn how word bedroom is used in English.
How does the software do it?
An algorithm is used to identify collocations and calculate their scores (logDice). The ones with the highest score will be included in the word sketch. This is how it is done:
First, the algorithm identifies all instances of adjective + bedroom combinations in the corpus. Then it takes the adjective and looks for all small + noun combinations in the corpus. Each time small is found together with bedroom, it gets a plus point and each time small is found with another noun it gets a minus point. (The actual algorithm is more complex but even this simplification is sufficiently for illustration.) As a result, the algorithm will classify collocations like this:
- adjectives that tend to combine with a large selection of other words, i.e. are very flexible in their use, will be classifield as weak collocations and will generally not be included in the word sketch
- adjectives that combine with only one or a handful of nouns (they ‘specialize’ in combining only with certain nouns) will result as strong collocations and will be included in the word sketch
- even collocations made up of frequent words such as small print will be included because the noun print does not combine with too many other adjectives so there is not much competition for small
By default, collocates in a word sketch will be sorted by score and the top 25 items will be displayed. The user can change this limit and also switch to sorting by frequency which puts less typical (and, in language teaching terminology, less advanced collocations) at the top.
How to analyse collocations in the British National Corpus (BNC)
Learn to work with collocations in Sketch Engine in 4 minutes.
 https://www.sketchengine.eu/wp-content/uploads/topic-classification-ententen20.png
532
1065
2024-02-21 16:01:022024-02-22 08:44:05Topics and genres in corpora
https://www.sketchengine.eu/wp-content/uploads/topic-classification-ententen20.png
532
1065
2024-02-21 16:01:022024-02-22 08:44:05Topics and genres in corpora https://www.sketchengine.eu/wp-content/uploads/lowercase.png
301
392
2020-01-06 16:16:592026-07-30 16:20:08Case sensitive and case insensitive corpus analysis
https://www.sketchengine.eu/wp-content/uploads/lowercase.png
301
392
2020-01-06 16:16:592026-07-30 16:20:08Case sensitive and case insensitive corpus analysis https://www.sketchengine.eu/wp-content/uploads/lemma-tag-lempos.png
301
392
2019-10-30 09:54:502020-04-07 15:21:00Words, tags, lemmas, lemposes, lowercase
https://www.sketchengine.eu/wp-content/uploads/lemma-tag-lempos.png
301
392
2019-10-30 09:54:502020-04-07 15:21:00Words, tags, lemmas, lemposes, lowercase https://www.sketchengine.eu/wp-content/uploads/corpus-from-web-blog2.png
307
400
2019-05-13 15:12:372026-05-29 14:18:49Build a corpus from the web
https://www.sketchengine.eu/wp-content/uploads/corpus-from-web-blog2.png
307
400
2019-05-13 15:12:372026-05-29 14:18:49Build a corpus from the web https://www.sketchengine.eu/wp-content/uploads/post-tags.png
301
392
2018-03-27 18:13:392026-07-27 16:31:59POS tags
https://www.sketchengine.eu/wp-content/uploads/post-tags.png
301
392
2018-03-27 18:13:392026-07-27 16:31:59POS tags https://www.sketchengine.eu/wp-content/uploads/multi-word-terms-wikipedia-automotive-industry.png
1203
1280
2018-01-16 17:34:142026-07-29 10:59:26The best term extraction
https://www.sketchengine.eu/wp-content/uploads/multi-word-terms-wikipedia-automotive-industry.png
1203
1280
2018-01-16 17:34:142026-07-29 10:59:26The best term extraction https://www.sketchengine.eu/wp-content/uploads/blog_th_fantastico.png
355
600
2017-11-29 12:02:182026-07-30 16:16:32Automatic thesaurus
https://www.sketchengine.eu/wp-content/uploads/blog_th_fantastico.png
355
600
2017-11-29 12:02:182026-07-30 16:16:32Automatic thesaurus https://www.sketchengine.eu/wp-content/uploads/2017-10-19_9-50-18.png
506
1169
2017-10-19 10:46:432020-12-02 18:03:45Corpus annotation and structures
https://www.sketchengine.eu/wp-content/uploads/2017-10-19_9-50-18.png
506
1169
2017-10-19 10:46:432020-12-02 18:03:45Corpus annotation and structures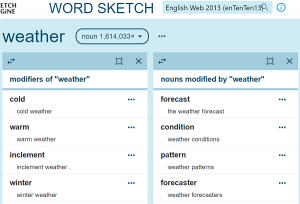 https://www.sketchengine.eu/wp-content/uploads/blog_ws_weather.png
407
600
2017-08-21 19:51:502026-07-29 11:22:28Most frequent or most typical collocations?
https://www.sketchengine.eu/wp-content/uploads/blog_ws_weather.png
407
600
2017-08-21 19:51:502026-07-29 11:22:28Most frequent or most typical collocations?

