What is ruSKELL?
ruSKELL is a version of SKELL for learners of Russian. SKELL is a simple tool for language learners to check how language is used by real users of the language. With ruSKELL, the learner can easily display Russian examples of use, collocations in Russian, and the Russian thesaurus with synonyms and similar words.
SKELL is based on Sketch Engine.
инструкция для ruSKELL на русском языке
Author: Культепина Ольга
RuSKELL (Sketch Engine for Learning the Russian Language) – корпусный онлайн-инструмент для изучения сочетаемости слов в контексте. Благодаря функциям RuSKELL пользователь может познакомиться с реальными контекстами употребления слова (“Примеры”), с распространенными сочетаниями слова (“Сочетаемость слова”) и с синонимами, антонимами и другими семантически близкими словами (“Похожие слова”).
Что значит “корпусный инструмент”? Если вы заведете слово корпусный в поисковую строку RuSKELL, то увидите сорок строк предложений с использованием этого прилагательного в различных сочетаниях:
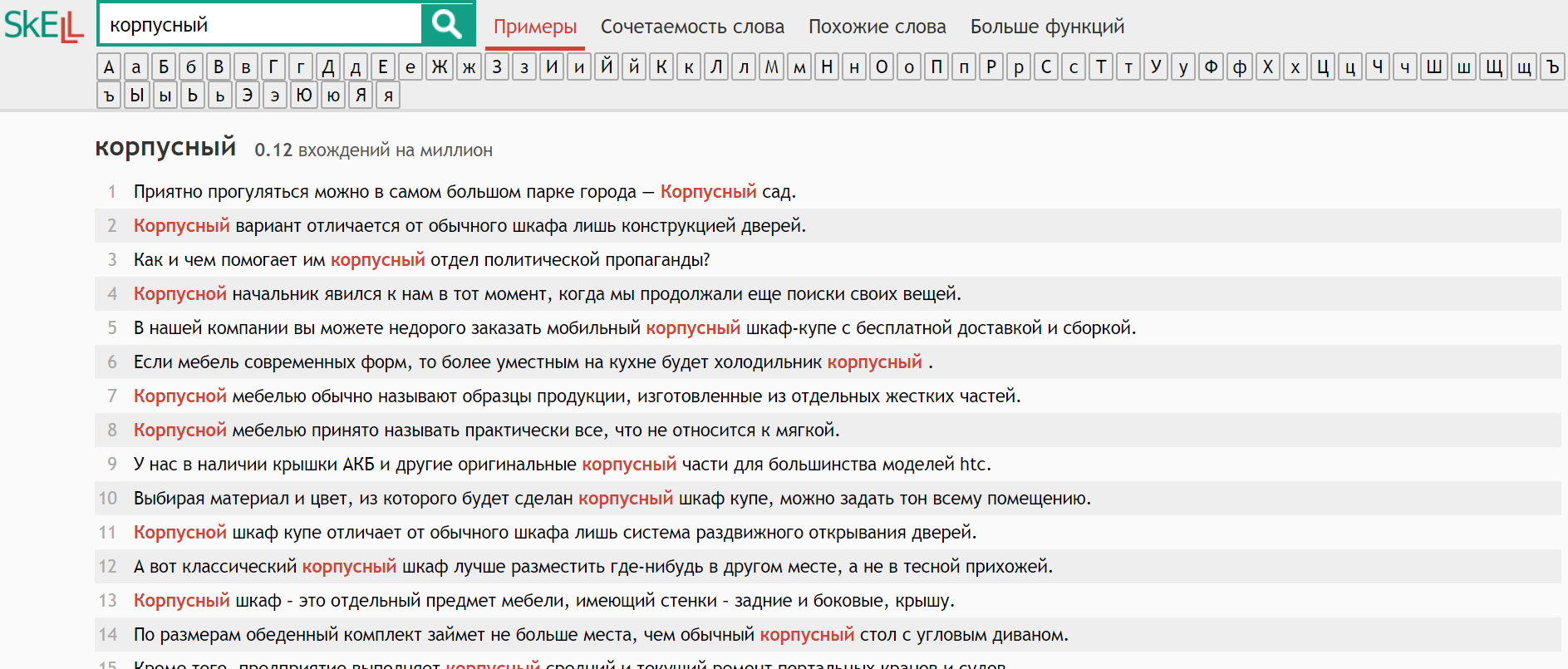
Эти примеры вы видите благодаря поиску в корпусе – в базе лингвистических данных. Корпус RuSKELL составляют тексты Рунета, закачанные из сети в 2011 году и обработанные для поиска основных сочетаемостей и хороших примеров.
Функция “Примеры” знакомит пользователей с контекстами употребления заданного слова. Вы можете вводить в поисковую строку целое слово, слово с пропуском букв, а также сочетания – полные и с пропусками:

На основе “Сочетаемости слова” пользователь может проверить самые распространенные сочетания слова, а также познакомиться с особыми сочетаниями: с идиомами, полуидиоматическими сочетаниями и даже высокочастотными фразеологизмами.Функция “Сочетаемость слова” показывает, в каких сочетаниях может встречаться слово. Зеленым полужирным выделены названия групп сочетаний, каждая из которых имеет не более 15 самых частотных слов, встречающихся в сочетании с словом-запросом. Например, если запрос – слово, то частотные слова в группе “глагол + слово(dat)”:
![]()
Функция “Похожие слова” позволяют посмотреть слова, которые встречаются в схожих контекстах и имеют наибольшее количество одинаковых коллокатов. Здесь представлены разные контекстные синонимы и антонимы, гиперонимы и гипонимы и другие слова, семантически близкие поисковому слову. В списке слова стоят по убыванию – от самого похожего слова (наибольший процент общих контекстов) до самого непохожего:

Download ruSKELL tutorial in Russian as PDF.
ruSKELL tutorial in English
Author: Культепина Ольга
RuSKELL (Sketch Engine for Learning the Russian Language) is a corpus-based tool for exploring word’s behavior in context. There are three functions that the resource offers. Users can look at a word’s real usage (‘Primery’), high-frequency collocations (‘Sochetaemost slova’) and similar words that have the same collocates (‘Pohozjiye slova’).
‘Primery’ presents relevant examples with a query-word. Users can look for the word or phrase and put .* for the missing parts of the word/phrase.
‘Sochetaemost slova’ is the function that builds the list of word’s collocations ranging by their frequency. The list consists of different groups of collocations which depend on the grammatical connection in the collocation. The name of each type of collocation is highlighted in green. Each group includes 15 collocations at maximum. For example, if a query if слово (‘slovo’ – a word), then the user finds in the group “глагол + слово(dat)”:
![]()
Users can collect the most typical frequent collocations and know the special phrases (idioms, colligations, set phrases) thanks to the function ‘Sochetaemost slova’.
The function ‘Pohozjiye slova’ lets users look at words that have similar collocations and could be called similar words to the query-word. There are synonyms and antonyms, hyperonyms and hyponyms etc. The words in the list are sorted by the most similar word (the greatest percent of common collocations) to the less similar one:
Download this ruSKELL tutorial in English as PDF.
The corpus was crawled by SpiderLing in 2011, encoded in UTF-8, cleaned and deduplicated. Tagged by RFTagger + TreeTagger. The corpus is cleared of obscene language, using a list of word, prohibited for naming in “.рф” domain space. The size of unzipped corpus is approximately 52 GB. It consists of 983,255,513 tokens or 10,394,826 unique lemmas.
RuSKELL was prepared by:
Valentina Apresjan (general guidance)
Andrey Shestakoff, Ekaterina Chernyak (mentors of corpus cleaning)
Timur Iskhakov (corpus cleaning)
Vít Suchomel (original corpus building)
Vít Baisa (interface development)
Olga Buivolova, Olga Kultepina, Anna Maloletnjaja (word sketch adaptations, testing)

Reference
APRESJAN, Valentina, Vít BAISA, Olga BUIVOLOVA and Olga KULTEPINA. RuSKELL: Online Language Learning Tool for Russian Language. In Tinatin Margalitadze, George Meladze. Proceedings of the XVII EURALEX International congress. Tbilisi: Ivane Javakhishvili Tbilisi State University, 2016. s. 292–299, 8 s. ISBN 978-9941-13-542-2.
