Concordance — examples of use in context
The concordance is the most powerful tool with a variety of search options. It can find words, phrases, tags, documents, text types or corpus structures and displays the results in context in the form of a concordance. The concordance can be sorted, filtered, counted and processed further to obtain the desired result. Despite being the most powerful tool, the concordance used with large corpora may find so many results that it can tedious to analyse and interpret them.
The view options allow displaying additional information such as lemmas, tags and other attributes, text types (metadata) or corpus structures.
The CQL search on the advanced tab is used for complex searches with unspecific criteria or optional criteria.

search criteria and frequency count
Manage macros
modify search criteria
download results
(max limit 1,000 lines for preloaded corpora, Access to unlimited wordlists)
Skema – manual concordance annotation
Change what you see and how it is displayed. Display tags and lemmas or corpus structures.
Randomly select only a number of lines from the complete results.
See the lines in a different order. Reorder randomly. By default lines are ordered in the same order as they are found in the corpus.
Sort the lines.
Remove or keep only lines matching specific criteria.
Sort Good Dictionary EXamples to the top.
Compute frequencies of the search word or other words or attributes in the concordance lines.
Compute collocations – words occurring near the search word. Only recommended if the word sketch cannot be used for some reason.
The Timeline function displays the changing frequency of a word or phrase over time
Show how the search word is distributed across the whole corpus.
Change from KWIC view to sentence view (=displaying complete sentences)
build a subcorpus from this concordance
Get concordance description
Add the result to favourites for easy access next time.
Sort by the Key Word In Context (the search word or phrase)
Sort by the 1st token (word) to the right.
Displays line details. Click to change the information displayed.
Click to display extended context.
How to use the concordance
Visit the related Quick start guide or watch this YouTube playlist.
In the interface, hover the mouse over icons, controls and other elements to display the tooltips. Click the highlighted words to learn about the functions and settings.
How does the concordance work?
The search always starts from the beginning of the corpus and the concordance lines are displayed in the order in which they are found in the corpus. Use the Shuffle or Random sample icons to change this.
By default and irrespective of which attribute is used for searching, the result is displayed as word form, i.e. as the source text of the corpus. The display of lemmas, tags and other attributes can be set in view options.
The icon to the left of each concordance line leads to text types (metadata) about the concordance lines. The user can set on or more of them to stay displayed permanently.
Concordance and other tools
All tools in Sketch Engine are linked to the concordance to allow users to see how the results of other tools are used in context.
The concordance is also the starting point for subcorpus building, the GDEX tool or complex frequency lists which cannot be obtained in the wordlist tool.
How to use the concordance
Searching
Hover the mouse over the different elements of the input form to learn about the different search options. Switch to the advanced tab for advanced criteria.
Working with the results
To learn to filter, sort, count, reorganize or process the results, hover the mouse over an icon or the question mark symbol (?) to display a tooltip which explains its function or watch the concordance videos on our channel.
Speed and corpus size
Sketch Engine is specifically designed to handle large corpora with speed. Any search will only take a few seconds to complete if the corpus size is under a billion words. It might take a bit of extra time for corpora over 1 billion words. Complex CQL searches containing regular expressions or frequency calculations on large corpora can take several minutes to complete.
Requirements for the concordance to work well
The concordance will work with any corpus even one which is not tokenized, lemmatized and tagged, however, adding these three features increases the usefulness immensely. Tokenization, lemmatization and tagging are carried out automatically upon uploading files to Sketch Engine provided the language is supported.
Result examples
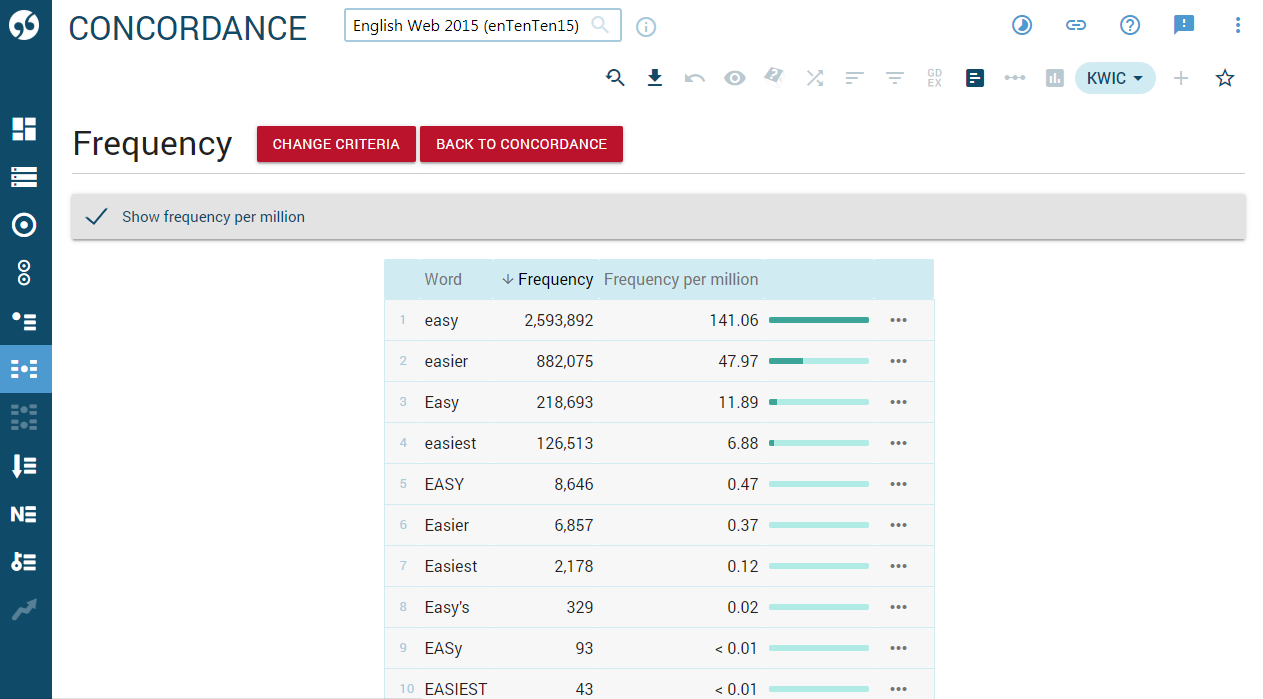
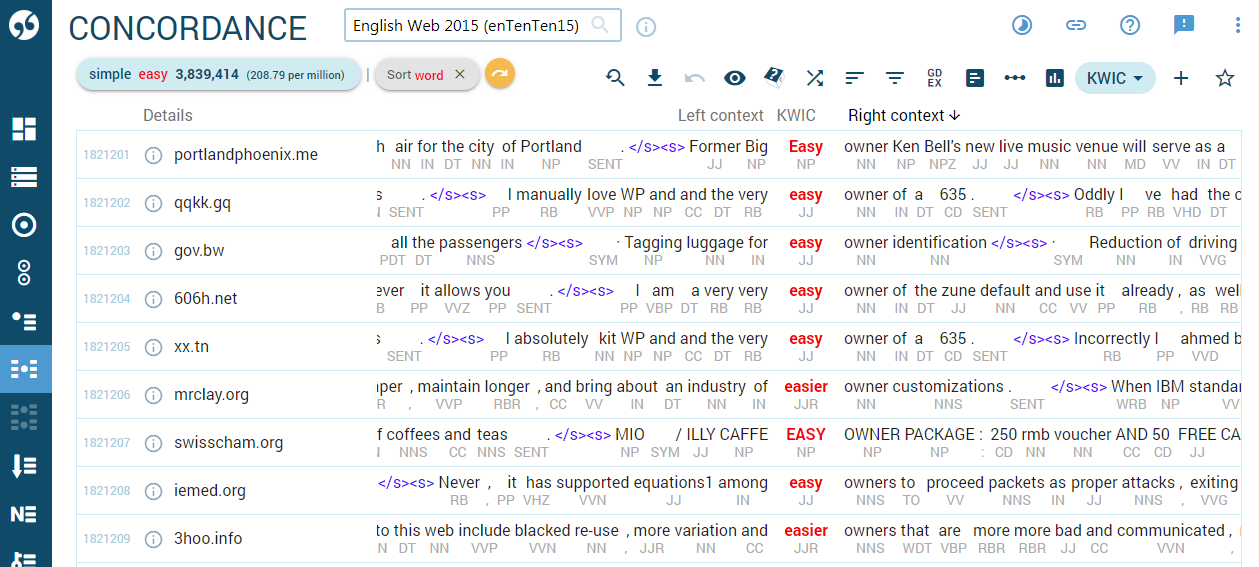
The concordance of easy sorted by the word that comes after easy with a jump to the first screen where the words start with the letter O. Other displayed information includes source websites, sentence boundaries and part-of-speech tags.
The statistics of how many lines from the above concordance come from each website. It was calculated using the frequency tool and the text type option.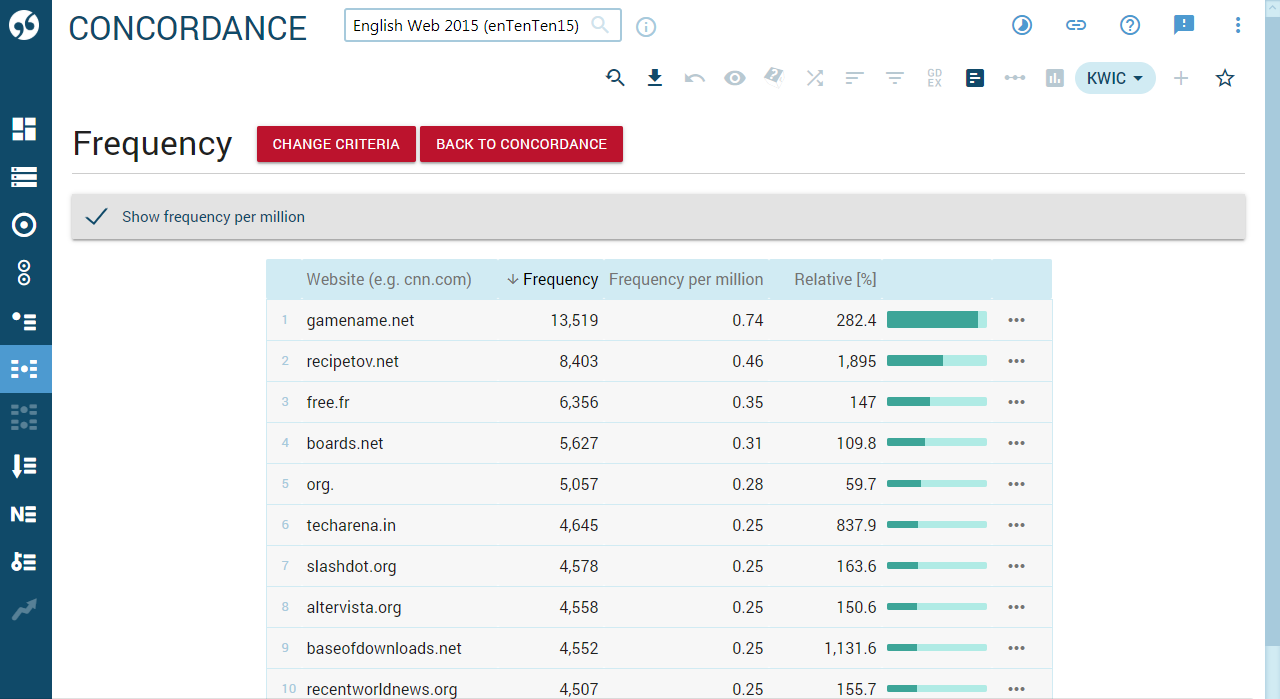
The statistics of the different word forms and the spelling variants of the word easy from the above concordance. It was calculated using the frequency tool and the KWIC word form option.