
Comment choisir un corpus
Avant de se servir des fonctionnalités de Sketch Engine, il faut choisir un corpus. Voici quelques conseils pour les usagers novices.
Option 1
- cliquez sur Choisir un corpus dans le menu de gauche
- indiquez la langue et sélectionnez-la – nous allons vous proposer un corpus qui peut vous convenir
OU - choisissez le corpus qui vous convient le mieux
- OU
tapez le nom du corpus et sélectionnez-le
Le tableau de bord du corpus va s’afficher et vous donner accès aux outils et fonctionnalités.
Option 2
Utilisez le sélectionneur de corpus tout en haut :
- tapez quelques lettres du nom du corpus ou de la langue
- choisissez le corpus
Le tableau de bord du corpus va s’afficher et vous donner accès aux outils et fonctionnalités.

Quel corpus choisir ?
Corpus mis en avant
Les corpus mis en avant permettent de s’initier aux corpus monolingues. Ils se distinguent des autres corpus par leur taille, leur qualité et par le fait qu’ils donnent accès à un maximum de fonctionnalités.
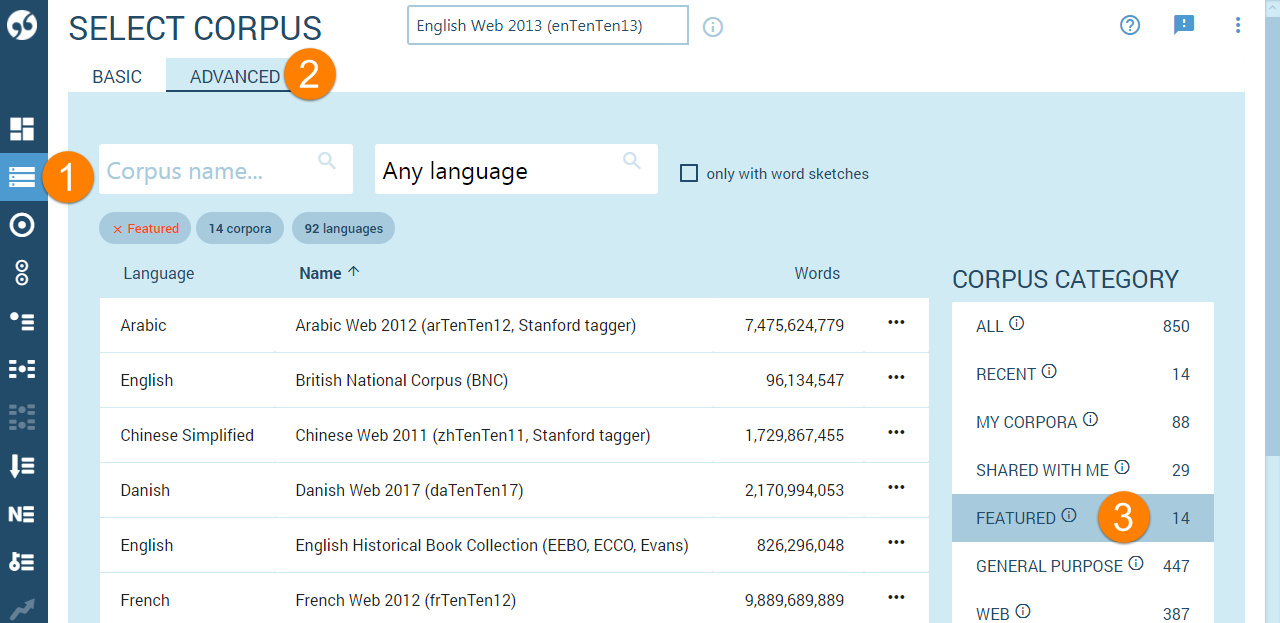
Pas de corpus mis en avant ?
Si vous ne trouvez pas de corpus mis en avant dans votre langue, cliquez sur TOUT . et servez-vous du champ de recherche. Indiquez une langue ou le nom d’un corpus.
TenTen
These corpora are excellent general purpose corpora. The main advantage is their large size, typically several billion words.
TenTen is a new generation of Web corpora. They are created by crawling the web in a sophisticated way. The downloaded texts undergo a complex process before they are included in the corpus. The downloaded texts are cleaned from non-text, e.g. navigation menus, legal text or small print, and duplicate text is removed. Downloaded texts are also evaluated and texts which are too short or contain too much content unsuitable for the use in a corpus are removed. TenTen stands for 1010 (10 billion) words. TenTen corpora in detail»
Timestamped
The main advantage of these corpora is timestamps, the information about texts and their time of publication. This fact enables you to carry out diachronic analysis; finding trending words, neologisms or archaisms. Moreover, the size of the corpora (from hundreds of millions up to billions of words) guarantees also coverage of less frequent words and expressions.
Timestamped corpora are created by crawling news articles from the web across the world. These news articles are detected by a system developed at Jozef Stefan Institute in Slovenia. Currently, the Timestamped English corpus with more than 28 billion words is the biggest corpus in Sketch Engine. Timestamped corpora in detail»
La taille du corpus
En général, on recommande l’exploration de grands corpus afin de réduire les biais. Regardez en quoi se distingue le célèbre corpus British National Corpus (BNC) d’autres corpus anglais sur Sketch Engine.
Corpus parallèles
La plupart des corpus parallèles sur Sketch Engine sont multilingues, c’est-à-dire, leur texte est accessible dans plusieurs langues. Ils peuvent aussi être interrogés partiellement, comme des corpus monolingues.
Sélectionner un corpus parallèle
On ne peut pas sélectionner un corpus directement ; il faut d’abord :
- choisir la première langue
- sélectionner une fonctionnalité (p.e., la recherche d’une concordance ou d’un profil lexical bilingue)
- au moment de paramétrer les critères, vous pouvez choisir la deuxième langue (si l’on utilise le concordancier, on peut même cliquer sur plusieurs langues)
OPUS corpora (recommended)
OPUS est une collection de textes traduits du web et couvre un large choix de sujets et de thèmes. Elle est disponible dans le plus grand nombre de langues et elle devrait être votre premier choix pour les corpus parallèles.. more Plus d’informations sur OPUS
EUROPARL corpora
Ce corpus a été créé à partir des travaux du Parlement européen et est disponible en 21 langues européennes. La nature du corpus en fait une excellente ressource pour les thèmes discutés au Parlement européen et pour la langue formelle générale. Les requêtes portant sur des domaines thématiques qui sont rares au Parlement européen peuvent ne pas donner de bons résultats. Plus d’informations sur EUROPARL
EUR-Lex Corpus
Un corpus créé à partir de documents traduits de l’Union européenne disponibles dans les 24 langues officielles de l’UE. Recommandé pour la langue formelle générale et les domaines couverts dans les documents de l’UE. Étant donné que la documentation de l’UE concerne de nombreux domaines, elle convient également à un usage général.. Plus d’informations sur EUR-Lex
Afficher l’information du corpus
Après avoir sélectionné un corpus, cliquez sur le bouton d’information (i) à côté du nom du corpus dans la partie centrale haute de l’écran.
