The Estonian National Corpus 2021 (Estonian NC 2021)
The Estonian National Corpus is a language corpus made up of texts collected from various domains. The last version of the corpus consists of the Estonian Reference Corpus (texts from the 90s until 2008 compiled by Tartu University), Estonian Web (2013, 2017, 2019, 2021), Estonian Wikipedia (2017 – talkpages, 2021 – articles), Estonian academic writing (2020–2021) and text type annotation (topics, genres). It contains 2.4 billion words, and the last data were crawled at the beginning of the year 2021.
Part-of-speech tagset
The Estonian National Corpus is a morphologically annotated corpus by the tagging tool EstNLTK v1.6 with the following part-of-speech tagset summary. The corpus texts also contain lemmatization when each word form from the corpus is assigned to its base form (lemma).
There are two types of POS tag attributes:
- the abbreviated tag contains only basic information about part of speech (see this overview),
- the longtag contains detailed information, including other categories for particular parts of speech.
Overview of Estonian National Corpus versions
The Estonian National Corpus has the following versions:
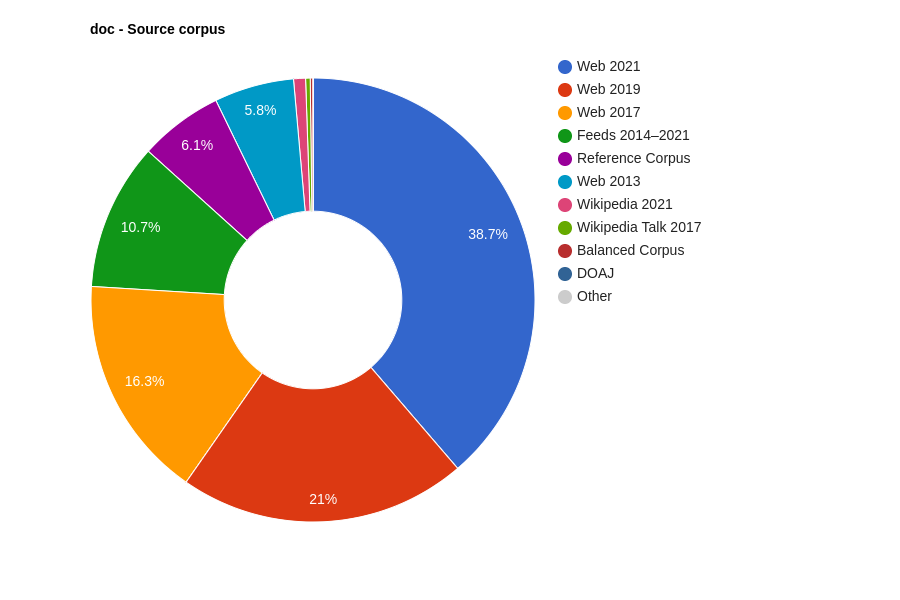
- Estonian National Corpus 2021 (Estonian NC 2021) – 2.4 billion words, comprised of Estonian Reference Corpus (90s–2008), Estonian Web (2013, 2017, 2019, 2021), timestamped Estonian Feeds corpus (2014–2021, 2020–2021), Estonian Wikipedia (articles: 2021, talkpages: 2017) and Estonian academic writing (2020–2021)
- Estonian National Corpus 2019 (Estonian NC 2019) – 1.5 billion words, comprised of Estonian Reference Corpus (90s–2008), Estonian Web (2013, 2017, 2019), Estonian Wikipedia (2017 and 2019) and Estonian DOAJ (2020). Cleaned, deduplicated. Text type annotation.
- Estonian National Corpus 2017 (Estonian NC 2017) – 1.1 billion words, comprised of Estonian Reference Corpus (90s–2008), Estonian Web (2013 and 2017), Estonian Wikipedia (2017)
- Estonian National Corpus 2013 (Estonian NC 2013) – 463 million words, comprised of the Estonian Reference Corpus (90s–2008), Estonian Web (2013)
- Estonian Reference corpus 1990-2008 (EstonianRC) – 203 million words (written texts).
Basic information
| Tokens | 2,945,431,278 |
| Words | 2,410,296,919 |
| Sentences | 196,615,233 |
| Documents | 11,744,940 |
Distribution of particular corpora
Tools to work with Estonian National Corpus
A complete set of Sketch Engine tools is available to work with this Estonian corpus to generate:
- word sketch – Estonian collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word and multi-word units
- word lists – lists of Estonian nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- text type analysis – statistics of metadata in the corpus
Changelog
Estonian National Corpus 2021 (Estonian NC 2021)
- 2.4 billion words – Estonian Reference Corpus (90s–2008), Estonian Web (2013, 2017, 2019, 2021), timestamped Estonian Feeds corpus (2014–2021, 2020–2021), Estonian Wikipedia (articles: 2021, talkpages: 2017) and Estonian academic writing (2020–2021). Cleaned, deduplicated. Tagged by EstNLTK with the Filosoft tagset. Text type annotation: topics, genres
Estonian National Corpus 2019 (Estonian NC 2019)
- 1.5 billion words – Estonian Reference Corpus (90s–2008), Estonian Web (2013, 2017, 2019), Estonian Wikipedia (2017 and 2019) and Estonian DOAJ (2020)
- text type annotation
Estonian National Corpus 2017 (Estonian NC 2017)
- 1.1. billion words – new crawled web data, Estonian Wikipedia + all previous versions
- improved word sketch grammar
Estonian National Corpus 2013 (Estonian NC 2013)
- 463 million words – Estonian Web corpus + written texts
Estonian Reference corpus 1990-2008 (EstonianRC)
- 203 million words (written texts)
Bibliography
For more information about the corpus including longtag summary, see the Estonian Reference corpus document.
Koppel, K., & Kallas, J. (2022). Eesti keele ühendkorpuste sari 2013–2021: mahukaim eestikeelsete digitekstide kogu. Eesti Rakenduslingvistika Uhingu Aastaraamat, 18, 207–228. https://doi.org/10.5128/erya18.12
Search the Estonian National Corpus
Sketch Engine offers a range of tools to work with the Estonian National Corpus.
Use Sketch Engine in minutes
Generating collocations, frequency lists, examples in contexts, n-grams or extracting terms is easy with Sketch Engine. Use our Quick Start Guide to learn it in minutes.

