
Keywords and term extraction — identifying typical words
Sketch Engine supports monolingual and bilingual term extraction. Keyword and term extraction is used to:
- extract terminology for use in translation and interpreting
- extract single word and multiword units which are typical of a corpus/document/text or which define its content or topic
- compare two corpora/documents/texts by identifying what is unique in the first corpus compared to the second one
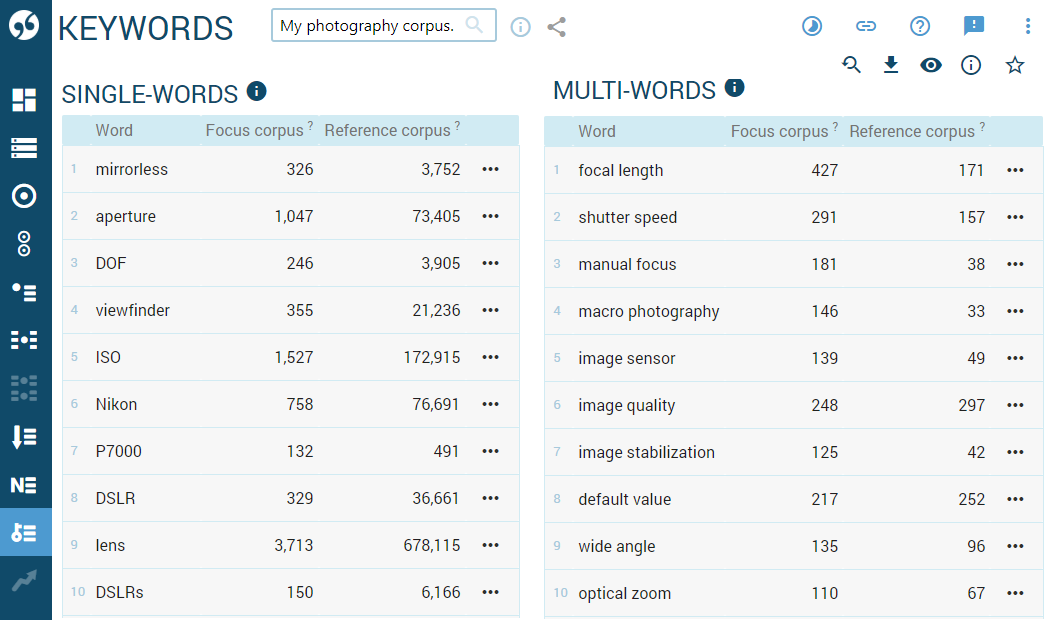
The result is divided into keywords (single word items) and terms (multiword items).
Read this blog post to learn about how exactly the term extraction works.
How to use keywords and term extraction
You will need to build a corpus first by uploading your own texts or by having Sketch Engine find relevant texts for you on the internet, or by combining both methods.
Visit the related Quick start guide or hover the mouse over icons, controls and other elements to display the tooltips. Click the highlighted words to learn about the functions and settings.
Keywords and terms - what is the difference?
Keywords
Keywords are individual words (tokens) which appear more frequently in the focus corpus than in the reference corpus. Any token can qualify for a keyword if it is used more frequently in the focus corpus than in the reference corpus. In reality, the result will include mainly nouns and adjectives because the frequencies of other parts of speech tend to be similar in all texts.
Terms
Terms are multi-word expressions which appear more frequently in the focus corpus than in the reference corpus and, additionally, match the typical format of terminology in the language. The format is defined in the term grammar.
The result of term extraction is displayed as lemmas. Gender lemmas are used for languages where the word form of an adjective has to match the gender of the noun.
Focus corpus and reference corpus
For the tool to work, at least 2 corpora in the language must exist. The corpus in which keywords and terms are identified is called a focus corpus. The corpus used for comparison is called a reference corpus.
Simple maths
The simple maths method is used to determine the keyness score of both keywords and terms. It works with normalized (relative, per million) frequencies in the focus and reference corpora.
What can I use it for?
Keyword and term extraction can be used for:
Terminology extraction
Terminology extraction extracts words which are typical for the topic of the document or corpus, i.e. they appear in the corpus more frequently than they would in general language. A large non-specialized corpus in the language is used to represent general language.
The default settings are normally sufficient for the extraction to provide high-quality results.
The results are displayed together with links to the sentences in both the focus and the reference corpora.
Extracting unique features of a corpus
This use is almost identical to terminology extraction. The difference is that the user may not only be interested in specialized lexis which is rare in general language but sometimes it might be interesting to look which medium-frequency words or even hight-frequency words are used more often than in general language. Use the slider on the advanced tab to focus the extraction on different parts of the frequency range.
Comparing corpora
Comparing two texts manually is not realistic if the two texts are very long. Even with short texts, statistical comparison can bring up phenomena which would go unnoticed when comparing manually.
Keywords and terms can be used to compare two corpora or subcorpora. When comparing subcorpora, each subcorpus can be in the same or different corpus.
The result will show what is typical of the focus (sub)corpus in comparison with the reference (sub)corpus.
Requirements for keywords and terms to work
Keywords will be extracted from any tokenized corpus. Terms can only be extracted from corpora which are tagged and lemmatized in languages for which a term grammar exists.
