Sketch Engine offers extraction of bilingual terminology in the streamlined term extraction interface OneClick Terms. In addition, bilingual terms can also be extracted from parallel corpora stored in the user’s account in Sketch Engine. Term extraction in two languages is supported from:
- non-aligned data, i.e. an original document and its translation are two separate files in one of the common document formats: PDF, DOC, DOCX, TXT, HTM, HTML
- aligned data, i.e. a translation memory (TMX, XLIFF) or a spreadsheet (XLS, XLSX)
No technical knowledge is required to extract terms from non-aligned or aligned data.
OneClick Terms

A sophisticated term extractor with monolingual and bilingual term extraction from common document formats.
Extracting bilingual terminology in OneClick Terms
- Visit OneClick Terms.
- No login is required for testing purposes. However, log in with your Sketch Engine account to see the complete results.
- Follow the instructions on the screen.
- When the Keep in Sketch Engine option is ticked, the data will also be processed into a parallel corpus and stored in MY CORPORA in the user’s Sketch Engine account. The parallel corpus can then be analysed using the tools in Sketch Engine.
- The extraction works best with the default settings. Only use Settings if you feel the criteria need to be changed.
- Results can be downloaded as TBX or CSV.
For best results
Longer texts produce better results. Terms which appear only once will be identified correctly but may not be matched to its correct translation.
Non-aligned data
- The documents must be translations of one another. (Not random texts about a similar topic.)
- Documents containing only text in one column produce best result.
- Documents with complex design such as advertisements, promotional leaflets or posters may be impossible to align and produce poor result.
Results
See below an example of extracted bilingual terms. For each term, OneClick Terms suggests up to 5 alternatives. The user should select the best translation. Only the selected option will be included in the download.
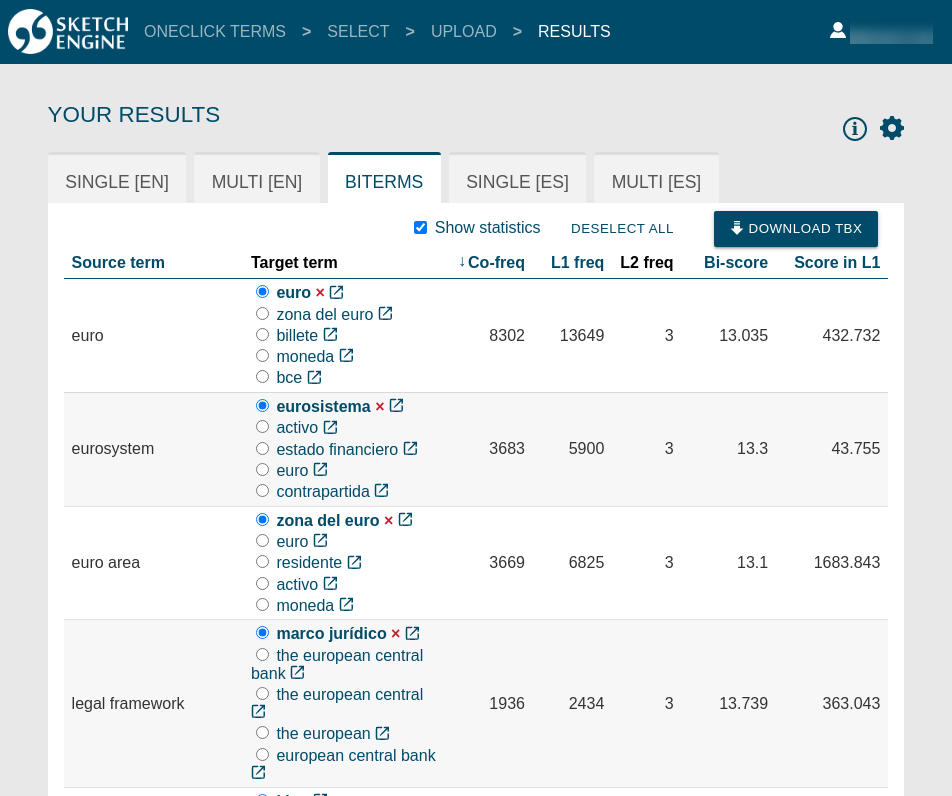
Example sentences
Optionally, the user can download the terms together with example sentences extracted from the documents or from the corpora in Sketch Engine. This setting is available after clicking DOWNLOAD TBX.
Sorting
By default, extracted terms are sorted by co-occurrence frequency which is the preferred option in most cases. Click the column header to change the sorting.
References
Bilingual Terminology Extraction in Sketch Engine. Vít Baisa, Barbora Ulipová, and Michal Cukr. In Ninth Workshop on Recent Advances in Slavonic Natural Language Processing, the Czech Republic, December 2015, pp. 61–67.
