jpWaC: Japanese corpus from the .jp domain
The Japanese web corpus (jpWaC) is a Japanese corpus made up of texts collected from the Internet. The corpus was prepared by Tomaž Erjavec using a list of URLs provided by Serge Sharoff at the University of Leeds. The standards of corpus preparation are described in the document A Corpus Factory for Many Languages (Kilgarriff et al. at LREC 2010).
The corpus was segmented, part-of-speech tagged and lemmatised using Chasen, an open-source toolset for Japanese. Word sketches were prepared by Irena Srdanovic.
Part-of-speech tagset
The Japanese WaC corpus has the following part-of-speech tagset legend.
Tools to work with the Japanese Web corpus
A complete set of Sketch Engine tools is available for working with this Japanese corpus and generating:
- word sketch – Japanese collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- word lists – lists of Japanese nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency lists of multi-word units
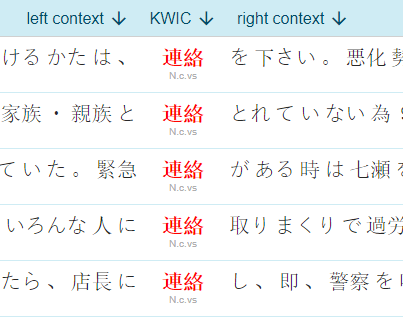
- concordance – examples in context
- keywords– terminology extraction of one-word
- text type analysis – statistics of metadata in the corpus
Changelog
version 2.0 (25 February 2011)
- added a new corpus attribute jp_tag which contains Japanese names of the part-of-speech tags
Bibliography
WaC corpora
BARONI, Marco, et al. The WaCky wide web: a collection of very large linguistically processed web-crawledcorpora. Language resources and evaluation, 2009, 43.3: 209-226.
Corpus factory method
Kilgarriff, A., Reddy, S., Pomikálek, J., & Avinesh, P. V. S. (2010, May). A corpus factory for many languages. In LREC.
Japenese word sketches
Srdanović, I., Naomi, I. D. A., Bučar, C. S., Kilgarriff, A., & Kovář, V. (2011). Japanese Word Sketches: Advances and Problems. Acta Linguistica Asiatica, 1(2), 63-82.
Search the Japanese corpus
Sketch Engine offers a range of tools to work with this Japanese corpus from the web.
Use Sketch Engine in minutes
Generating collocations, frequency lists, examples in contexts, n-grams or extracting terms is easy with Sketch Engine. Use our Quick Start Guide to learn it in minutes.
