myTenTen21: Burmese corpus from the web
The Burmese Web Corpus (myTenTen21) is a corpus made up of texts collected from the Internet by SpiderLing in January and February 2021. The corpus belongs to the TenTen corpus family that is a set of web corpora built using the same method with a target size 10+ billion words. Sketch Engine currently provides access to TenTen corpora in more than 40 languages.
For detailed information about TenTen corpora, see Common TenTen corpora attributes.
Part-of-speech tagset
The myTenTen21 corpus was tagged by RFTagger trained on myPOS corpus and uses the following tagset.
Tools to work with the Burmese corpus
A complete set of tools is available to work with this Burmese Web corpus (myTenTen21) to generate:
- keywords – terminology extraction of one-word units
- word lists – lists of Burmese nouns, verbs, adjectives, etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- keywords– terminology extraction of one-word units
- text type analysis – statistics of metadata in the corpus
Further information about texts in the corpus
Counts
| Tokens | 716 million |
| Words | 557 million |
| Sentences | 23 million |
| Web pages | 895 thousand |
Distribution of websites the corpus has been made from 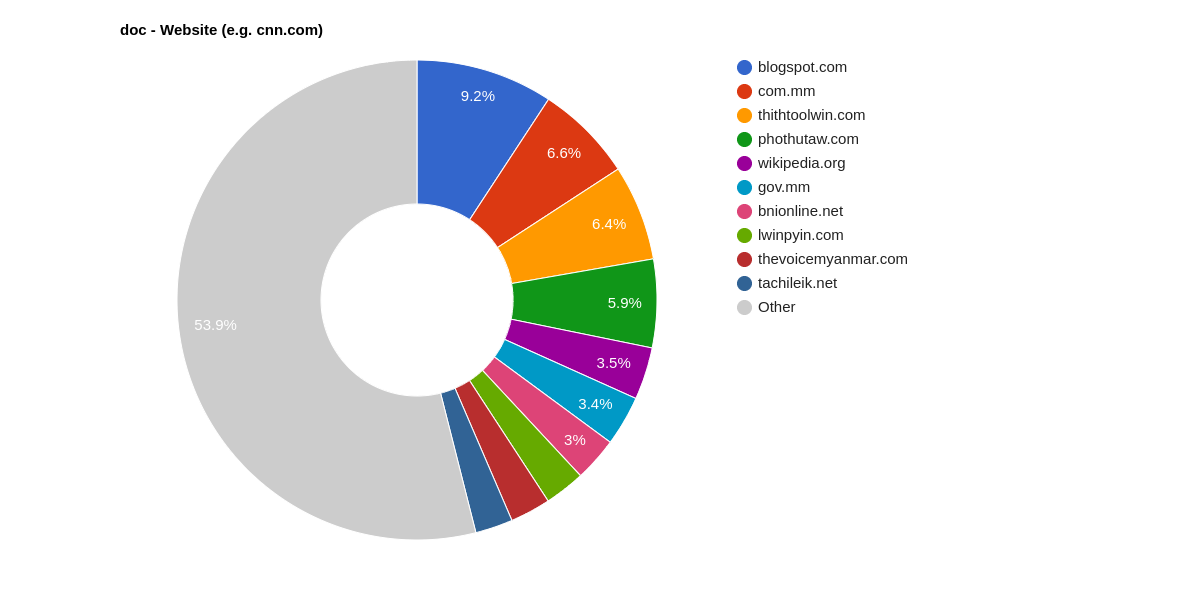
Bibliography
TenTen corpora
Jakubíček, M., Kilgarriff, A., Kovář, V., Rychlý, P., & Suchomel, V. (2013, July). The TenTen corpus family. In 7th International Corpus Linguistics Conference CL (pp. 125-127).
Suchomel, V., & Pomikálek, J. (2012). Efficient web crawling for large text corpora. In Proceedings of the seventh Web as Corpus Workshop (WAC7) (pp. 39-43).
Search the Burmese corpus
Sketch Engine offers a range of tools to work with this Burmese corpus.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.
