srWaC – Serbian corpus from the web
The Serbian web corpus (srWaC) is a Serbian corpus made up of texts collected from the Internet. The corpus was prepared according to standards described in the document A Corpus Factory for Many Languages (Kilgarriff et al. at LREC 2010). The corpus was created in January 2014 and its total size is over 476 million words.
Part-of-speech tagset
The srWaC corpus was PoS tagged with MULTEXT-East Croatian part-of-speech tagset version 5.
Tools to work with the Serbian corpus
A complete set of tools is available to work with this Serbian corpus to generate:
- word sketch – Serbian collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- word lists – lists of Serbian nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
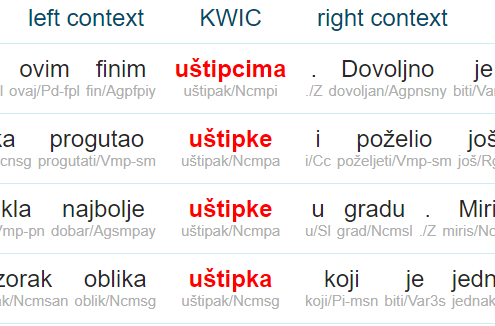
- concordance – examples in context
- keywords– terminology extraction of one-word and multi-word units
- text type analysis – statistics of metadata in the corpus
Changelog
hrWaC 2.2 (July 2017)
- improved tokenization
- new word sketches
- added further metainformation: year of crawling, language (Croatian, Serbian)
hrWaC 2.0 (May 2014)
- crawled in January 2014
- 1.2 billion words
Bibliography
BARONI, Marco, et al. The WaCky wide web: a collection of very large linguistically processed web-crawledcorpora. Language resources and evaluation, 2009, 43.3: 209-226.
Corpus factory method
Adam Kilgarriff, Siva Reddy, Jan Pomikálek, and Avinesh PVS. A corpus factory for many languages. In LREC workshop on Web Services and Processing Pipelines, Malta, May 2010.
Search the srWaC corpus
Sketch Engine offers a range of tools to work with this Serbian corpus from the web.
Use Sketch Engine in minutes
Generating collocations, frequency lists, examples in contexts, n-grams or extracting terms. Use our Quick Start Guide to learn it in minutes.
