What is term extraction?
Term extraction or terminology extraction is an automatic method of analysing text in order to identify phrases which fulfil the criteria for terms. Terminology extraction has its use in translation and terminology management but also in text analytics where it is used for topic modelling, data mining and information retrieval from unstructured text.
The best term extraction
The best term extraction is one that provides a clean list of terms that requires very little manual cleaning, if any at all. Many traditional methods relying mainly on the frequency in the focus text can only extract term candidates which the user has to go through and clean. The manual cleaning can be avoided by making use of linguistic criteria in combination with statistics. If a phrase is to qualify as a term, it should fulfil these criteria:
- It matches the structure that a term in the language can have.
- It appears more frequently in the focus text than in general text.
The following text explains how Sketch Engine implements these principles into their term extraction and into OneClick Terms, the term extractor interface.
The result screen of the term extraction in OneClick Terms. The results can be download. The statistics can be hidden.

Switch between lists of single-word terms and multi-word terms.
A direct link to the relevant Wikipedia article helps learn about the meaning of the keyword or term.
The frequency count opens a concordance – a new window with the sentences the word comes from.
Download results in formats allowing editing as well as importing into a CAT tool or terminology management software.
More settings for extracting terminology such as filtering out words with upper cases or prefer more rare words, etc.
Term structure
In each language, a term can have a different format. In most situations, the requirement is for a term to be a noun phrase. For example, a term in English can be composed of nouns (N), adjectives (J) and also prepositions so the phrase should match one of these patterns N+N, N of N, J+N, J+J+N, J+N of N, J+N of J+N etc. while preposition + article + adjective is unlikely to be considered a term.
Sketch Engine and OneClick Terms use a specific rules for each langauge describing the permitted structures that terms in that language can have.
Term frequency
If we analyse texts from tabloid newspapers and texts from books on accounting, we are likely to find income tax and best way in both of them. Both phrases match the structure of a term in English (N+N and J+N respectively), however, the frequencies are likely to differ. While the frequency of best way is likely to be similar in both texts, the frequency of income tax is likely to be much higher in texts on accounting. This is how the system can automatically tell a frequent phrase from a term and will identify income tax as a term.
Only units (=terms) which are more frequent in your text than they would be in general language is regarded as terms. General language is represented by a large general corpus used as a reference corpus.
Linguistic tools for term extraction
Part-of-speech tagging
To achieve the best possible quality, the focus text must be tagged for parts of speech first. This will ensure that each phrase in the text can be matched against the allowed term structures. Sequences of words containing undesirable parts of speech can be excluded easily with the aim to produce a clean list of relevant terms.
Texts which the user uploads in Sketch Engine or OneClick Terms are tagged for parts of speech automatically.
Lemmatization (morphological analysis)
Another important prerequisite is lemmatization. This will ensure that frequencies are calculated correctly even if the phrase is used in a different form, e.g. the frequency of income tax and income taxes should be calculated together. This is vital especially for languages such as Spanish, Russian, German and many others where each verb, noun and other parts of speech can have various endings and word form variations.
Texts which the user uploads in Sketch Engine or OneClick Terms are lemmatized automatically.
All of these tools and technology make up the term extraction functionality of Sketch Engine which is presented to the user in the easy-to-use term extraction interface of OneClick Terms.
How to use OneClick Terms for best term extraction results?
OneClick Terms is a simple interface to a powerful high-quality term extractor. It uses the technology developed by Sketch Engine, a leading corpus building and corpus analysis software.
1. tag and lemmatize
Just drag and drop your text into the OneClick Terms online interface – the part-of-speech tagging and lemmatization will happen automatically. No technical knowledge is required.
2. identify term candidates and compare frequencies
The next step in OneClick Terms is to calculate the frequency of each phrase that matches the term structure. All of this happens automatically. First, the frequency in the focus text is calculated, then the frequency of the same phrase in general language text is calculated. Large text corpora with a size of up to 25 billion words are used as samples of general language. Their enormous size ensures that all possible topics, domains and specializations are included and there is no bias towards a particular topic. Absolute frequencies are converted to relative ones to make the comparison between the focus text and the corpus possible. A score indicating the ‘termness’ of each phrase is calculated and the list of extracted terms is presented to the user.
3. download extracted terms
Download the results in txt, csv or tbx format and open them in your preferred editor or upload them directly into your CAT tool or terminology management software.
Try OneClick Terms
OneClick Terms work even without registration, just drag and drop your text into the interface.
To gain access to the complete results, create a free 30-day trial account or a paid account.
Where to go next?
 https://www.sketchengine.eu/wp-content/uploads/topic-classification-ententen20.png
532
1065
2024-02-21 16:01:022024-02-22 08:44:05Topics and genres in corpora
https://www.sketchengine.eu/wp-content/uploads/topic-classification-ententen20.png
532
1065
2024-02-21 16:01:022024-02-22 08:44:05Topics and genres in corpora https://www.sketchengine.eu/wp-content/uploads/lowercase.png
301
392
2020-01-06 16:16:592020-07-02 11:31:20Case sensitive and insensitive corpus analysis
https://www.sketchengine.eu/wp-content/uploads/lowercase.png
301
392
2020-01-06 16:16:592020-07-02 11:31:20Case sensitive and insensitive corpus analysis https://www.sketchengine.eu/wp-content/uploads/lemma-tag-lempos.png
301
392
2019-10-30 09:54:502020-04-07 15:21:00Words, tags, lemmas, lemposes, lowercase
https://www.sketchengine.eu/wp-content/uploads/lemma-tag-lempos.png
301
392
2019-10-30 09:54:502020-04-07 15:21:00Words, tags, lemmas, lemposes, lowercase https://www.sketchengine.eu/wp-content/uploads/corpus-from-web-blog2.png
307
400
2019-05-13 15:12:372026-05-29 14:18:49Build a corpus from the web
https://www.sketchengine.eu/wp-content/uploads/corpus-from-web-blog2.png
307
400
2019-05-13 15:12:372026-05-29 14:18:49Build a corpus from the web https://www.sketchengine.eu/wp-content/uploads/post-tags.png
301
392
2018-03-27 18:13:392026-05-11 09:29:32POS tags
https://www.sketchengine.eu/wp-content/uploads/post-tags.png
301
392
2018-03-27 18:13:392026-05-11 09:29:32POS tags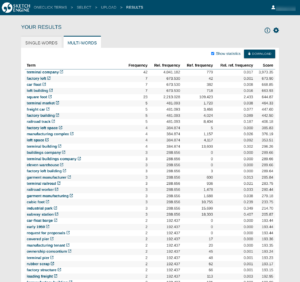 https://www.sketchengine.eu/wp-content/uploads/multi-word-terms-wikipedia-automotive-industry.png
1203
1280
2018-01-16 17:34:142024-10-15 11:42:41The best term extraction
https://www.sketchengine.eu/wp-content/uploads/multi-word-terms-wikipedia-automotive-industry.png
1203
1280
2018-01-16 17:34:142024-10-15 11:42:41The best term extraction https://www.sketchengine.eu/wp-content/uploads/blog_th_fantastico.png
355
600
2017-11-29 12:02:182021-01-07 15:00:12Automatic thesaurus
https://www.sketchengine.eu/wp-content/uploads/blog_th_fantastico.png
355
600
2017-11-29 12:02:182021-01-07 15:00:12Automatic thesaurus https://www.sketchengine.eu/wp-content/uploads/2017-10-19_9-50-18.png
506
1169
2017-10-19 10:46:432020-12-02 18:03:45Corpus annotation and structures
https://www.sketchengine.eu/wp-content/uploads/2017-10-19_9-50-18.png
506
1169
2017-10-19 10:46:432020-12-02 18:03:45Corpus annotation and structures https://www.sketchengine.eu/wp-content/uploads/blog_ws_weather.png
407
600
2017-08-21 19:51:502026-04-01 13:57:57Most frequent or most typical collocations?
https://www.sketchengine.eu/wp-content/uploads/blog_ws_weather.png
407
600
2017-08-21 19:51:502026-04-01 13:57:57Most frequent or most typical collocations?