Error corpus from English Wikipedia
The Error corpus from English Wikipedia is an error corpus made up of a sample of texts collected from the English Wikipedia. This is an only 1-million-word sample from English Wikipedia created in March 2017.
Types of errors
The automatic tool marks six types of errors in texts:
| Code | Description | Example |
| lexicosemantic | lexico-semantic errors | mentor | a mentor |
| punct | punctuation errors | ! | . |
| spelling | misspellings | intensly | intensely |
| style | typos relating to style | |
| typographical | mistakes relating to typography | ‘ | “ |
| unclassified | other types of typos | is to be | was |
Part-of-speech tagset
This English error corpus was tagged by TreeTagger using Penn TreeBank tagset with Sketch Engine modifications.
Tools to work with the error corpus
A complete set of tools is available to work with this English error corpus to generate:
- error tagging – errors marked by the type of error (spelling, typography, etc.)
- word sketch – English collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- word lists – lists of English nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
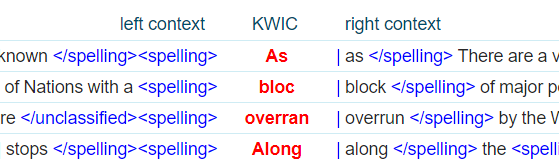
- concordance – examples in context
- keywords– terminology extraction of one-word
- text type analysis – statistics of metadata in the corpus
Changelog
initial version – sample (March 2017)
- 1-million-word sample from English Wikipedia
Bibliography
KLETEČKA, Jiří. Wikipedia Learner’s Corpus [online]. Brno, 2017 [cit. 2018-03-07]. Available from:
Search the error corpus
Sketch Engine offers a range of tools to work with this error corpus from the English Wikipedia.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.
