
Discover new words
A dedicated service for publishers, lexicographers and content developers to deliver information about new and trending words in English discovered in the latest time-annotated linguistic corpora.
Neologisms and diachronic analysis of word usage
Trends is a feature for detecting words which undergo changes in the frequency of use in time (diachronic analysis). Trends identify words whose use increases or decreases over time.
Lexicologists can use trends to identify new words (neologisms) and historians can use trends to identify the point in time when a word started to be used, stopped being used or when it saw an unusually increased or decreased use.
For a detailed description of the algorithms and comparison of their performance, see Ondřej Herman’s thesis.
Which corpora can be used?
Trends will only work with a corpus with time stamps, i.e. a corpus whose documents are annotated with a (publication) date. The largest corpora in Sketch Engine compatible with trends are Trends corpora available in many languages, such as the largest corpus English Trends.
Preloaded corpora with trends
Using Trends
A timestamped corpus has to be selected for Trends to work. Use the BASIC or ADVANCED tab to set the criteria if necessary.
Use the tooltips attached to the elements of the input forms to learn about the individual settings and controls.
The default settings do not have to be changed to produce a result.
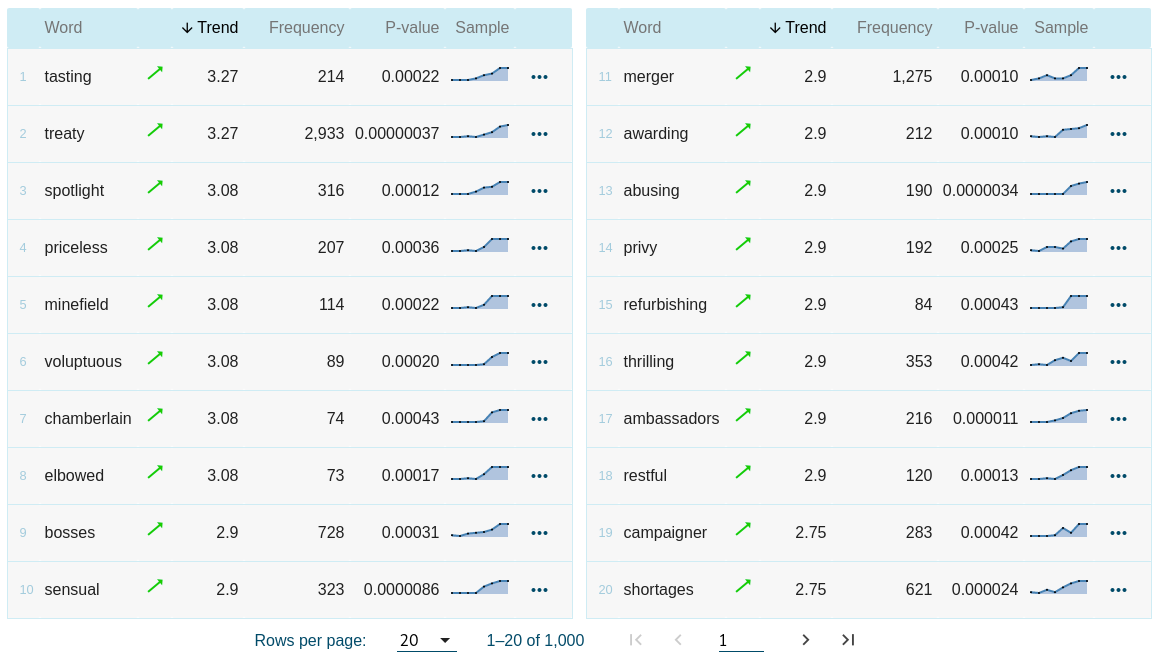
By default, the results are sorted by the absolute value of the change. The words with the biggest change will be at the top irrespective of whether the change was positive (=growing usage) or negative (=decreasing usage).
Preparing data for use with Trends
In order for your corpus to use Trends, it must be annotated with timestamps.
Size and balance
There is no minimum requirement for corpus size but to receive usable results, the corpus should contain a decent amount of data for each period. At present, our smallest corpus with trends is the Anthology Reference Corpus with 38 million words. It is unlikely to receive usable results from a corpus of 1 million words.
The balance of periods is also important. If most texts belong to only a few periods from a wide range of periods, the results will be biased towards those periods.
Configuring a corpus for use with Trends
Data have to be annotated with timestamps, i.e. metadata saying when the particular text was published/written. The timestamp attribute is user-defined (e.g. pub_date). Most corpora only have one timestamp attribute, but the same corpus can contain several – in that case, the user can select which of them should be used for the computation. It is not necessary to have the timestamp in each document, but trends will be computed only from documents containing them.

After adding annotations, the corpus needs to be recompiled.
Then, the attribute should be selected in Manage corpus → Configure → Expert settings → Diachronic attributes. Once the timestamp attribute is selected, the corpus needs to be recompiled again.
Examples of valid values
All values within the same corpus must have the same format.
1958
1964-05
1994-03-27
year2004
Y2011M04D12
Invalid values
2004Mar14 – the month will be lost
If you have problems with setting things up, please ask for assistance.
Result screen description
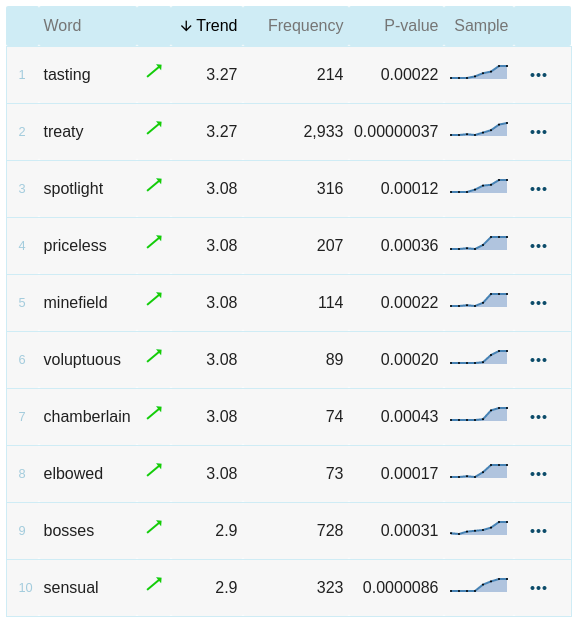
Trend
the value indicating the degree of change
P-value
expresses the degree of change, see p-value
Frequency
the frequency in the corpus (number of hits)
Clicking the three dots will launch a local menu containing links to a concordance and a frequency list broken down by the available time interval.
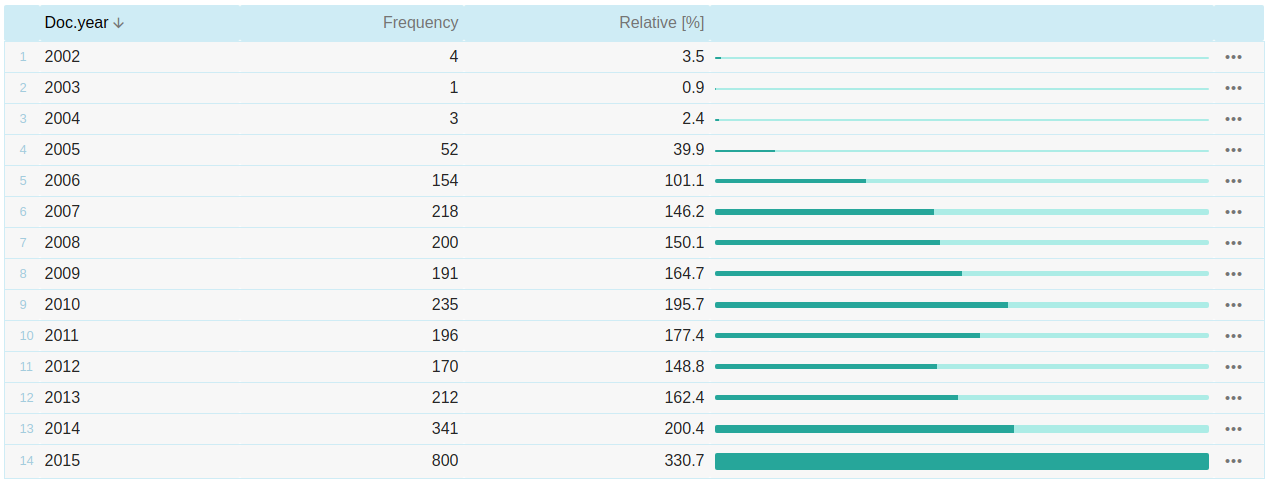
Frequency list broken down by the year (the time interval available depends on how the corpus is annotated, corpora can be annotated for smaller or bigger units such as months or decades).
Frequency – absolute frequency
Relative [%] – relative text type frequency
Clicking the three dots will launch a local menu containing links to a concordance of the word from the given period only (= positive filter) or the word from all periods but not the one that was clicked (= negative filter).
Terminology
p-value (statistical significance) – a function of the observed sample results that is used for testing a statistical hypothesis
slope (trend direction) – a number that describes the direction and the steepness of a line
Theil-Sen – a non-parametric method that finds the median slope among all lines designed by pairs of sample points
Linear regression – a method used for modeling the linear relationship between a dependent variable and one or more explanatory variables
Bibliography
Adam Kilgarriff, Ondřej Herman, Jan Bušta, Pavel Rychlý and Miloš Jakubíček. DIACRAN: a framework for diachronic analysis (presentation). In Corpus Linguistics (CL2015), United Kingdom, July 2015.
Ondřej Herman and Vojtěch Kovář. Methods for Detection of Word Usage over Time. In Seventh Workshop on Recent Advances in Slavonic Natural Language Processing, RASLAN 2013. Brno: Tribun EU, 2013, pp. 79–85. ISBN 978-80-263-0520-0.
Ondřej Herman (2013). Automatic methods for detection of word usage in time. Bachelor thesis. Masaryk University, Faculty of Informatics.
How to compute trends - local installation
A script “mktrends” is part of Sketch Engine. If you have a local installation, you can call the script directly in your command-line. Without parameters, it gives this information.
usage: /usr/bin/mktrends CORPUSNAME STRUCTATTR ATTR STATISTIC LIMIT EPOCH_LIMIT [SUBCORPFILE] EPOCH_LIMIT: attribute values with smaller norm are discarded LIMIT: words with fewer occurrences are skipped METHODS: comma-separated list of methods to compute possible values are: linreg_nonzero, mkts_all, mkts_nonzero, linreg_all example: /usr/bin/mktrends bnc bncdoc.year word mkts_all 100 100000
