ParlaMint corpora: 17 corpora of parliamentary debates
The ParlaMint corpus is a collection of 17 multilingual comparable corpora consisting of parliamentary debates. The ParlaMint corpora include debates of 17 national parliaments: Bulgarian parliament, Belgian parliament (French and Dutch language), British parliament (English language) Czech parliament, Croatian parliament, Danish parliament, Dutch parliament, French parliament, Hungarian parliament, Icelandic parliament, Italian parliament, Latvian parliament, Lithuanian parliament, Polish parliament, Slovenian parliament, and Spanish parliament.
The ParlaMint corpora were created as part of the project ParlaMint financially supported by CLARIN ERIC (European Research Infrastructure Consortium). The project website is available in research infrastructure CLARIN, the corpus data can be accessible from the CLARIN repository.
The original version of corpora is created from a modified CONLL format (a specific format of vertical with a parse tree representing syntactic structures) including a specific format of word sketches generated from this format based on dependency parsing. The Sketch Engine version of corpora is processed by pipelines available for a particular language with a standard format of word sketches. The ParlaMint corpora contain rich metadata with various information about the speaker, speech, time period, etc. The time range of the majority of the parliamentary debates is from 2015 to mid-2020.
Tools to work with the ParlaMint corpora 2.1
A complete set of Sketch Engine tools is available to work with these parliamentary corpora to generate:
- word sketch – collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word and multi-word units
- word lists – lists of nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- text type analysis – statistics of metadata in the corpus
The set of tools may vary depending on the particular language.
Citation & reference
Erjavec, Tomaž; et al., 2021, Linguistically annotated multilingual comparable corpora of parliamentary debates ParlaMint.ana 2.1, Slovenian language resource repository CLARIN.SI, ISSN 2820-4042, http://hdl.handle.net/11356/1431.
Search the ParlaMint corpora
Sketch Engine offers a range of tools to work with these ParlaMint corpora of parliamentary debates.
Working with the corpus
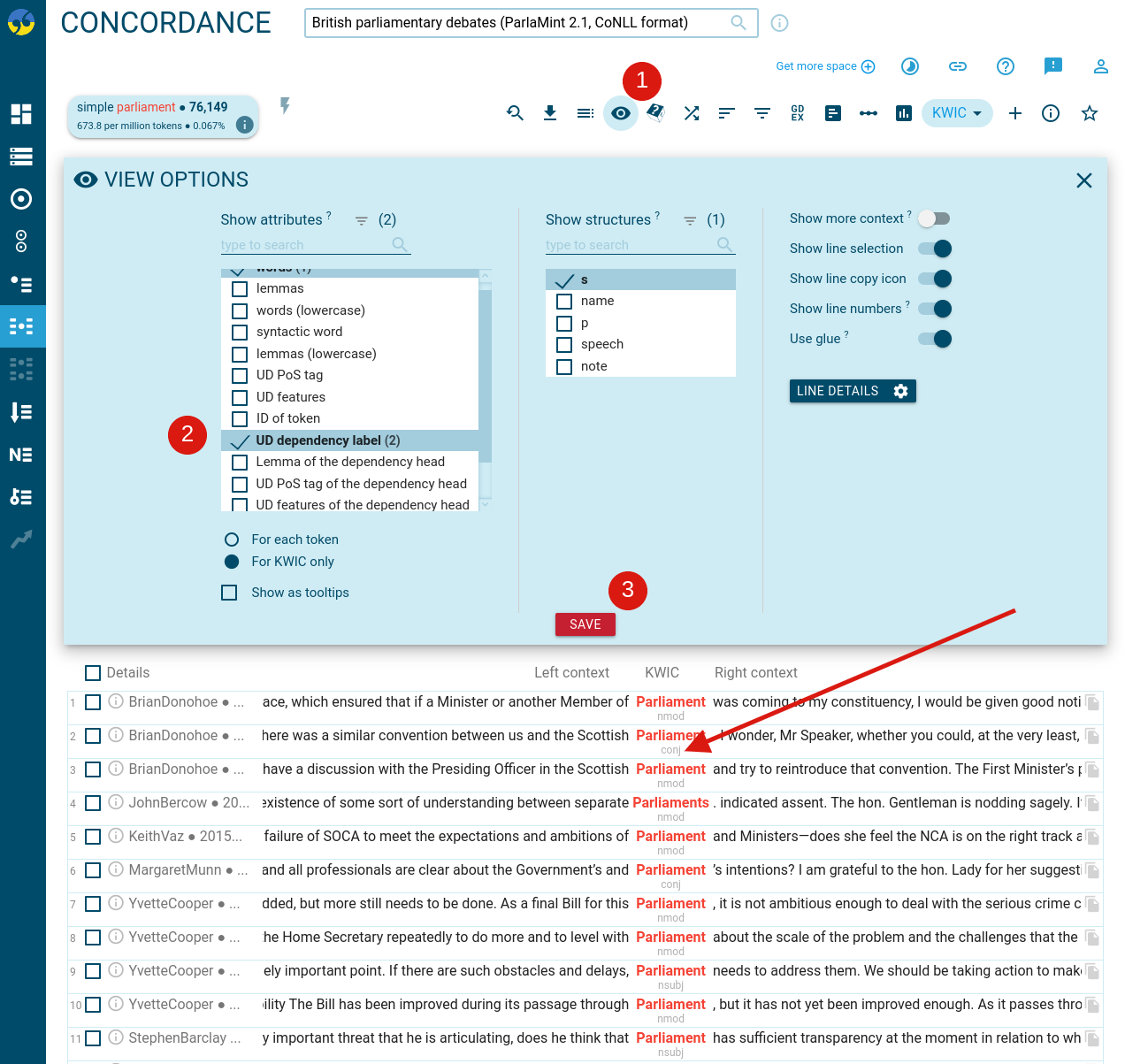
The ParlaMint corpora with CoNLL format include apart from standard annotation such as lemmas and part-of-speech tags, also the morphological features, syntactic dependencies, and the 4-class CoNLL-2003 named entities. These syntactic dependencies were used for generating word sketches which means the word sketches are based on the syntactic labels.
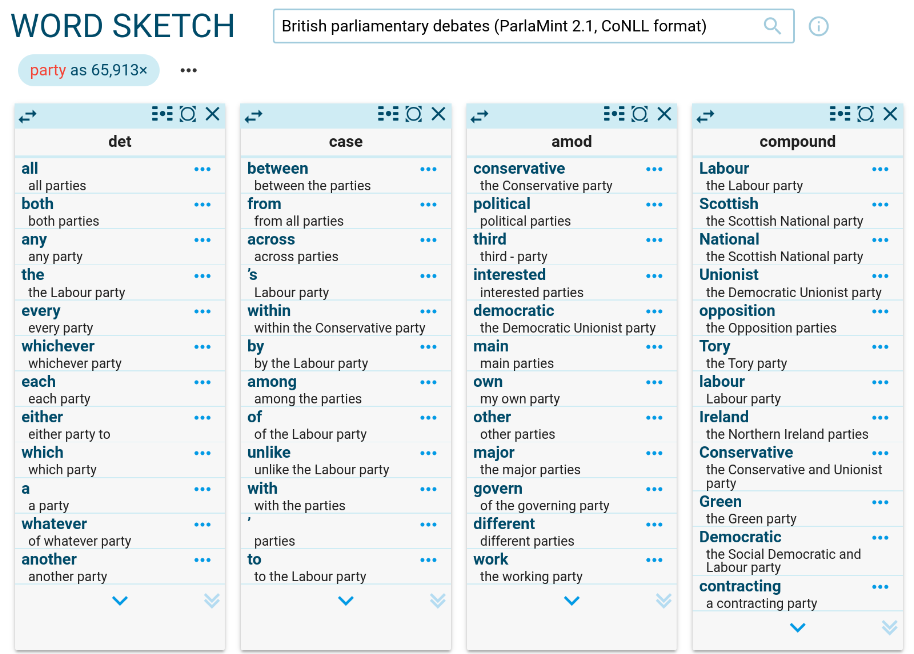
These specific annotations can be also displayed in other tools, e.g. concordance.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.
