
Word Sketch — collocations and word combinations
The word sketch processes the word’s collocates and other words in its surroundings. It can be used as a one-page summary of the word’s grammatical and collocational behavior. The results are organized into categories, called grammatical relations, such as words that serve as an object of the verb, words that serve as a subject of the verb, words that modify the word etc. The words which will be included in the analysis are defined by rules written in the sketch grammar that detects potential collocations.

change search criteria
download results
display or hide scores, frequency, change sorting, activate clustering
filter results by typing characters or a word
screen details – display search parameters and link to word sketch grammar
visualisation – display collocations as diagram
favorites – bookmark this word sketch for easy access
move this column to a different position
display all sentences or examples from which collocations in this column were collected
only keep this column and hide the others
hide this column
change the part of speech
use this word as the search word for other tools
How to use the word sketch
Visit the related Quick start guide or watch this video.
Hover the mouse over icons, controls and other elements to display the tooltips. Click the highlighted words to learn about the functions and settings.
What makes the word sketches unique?
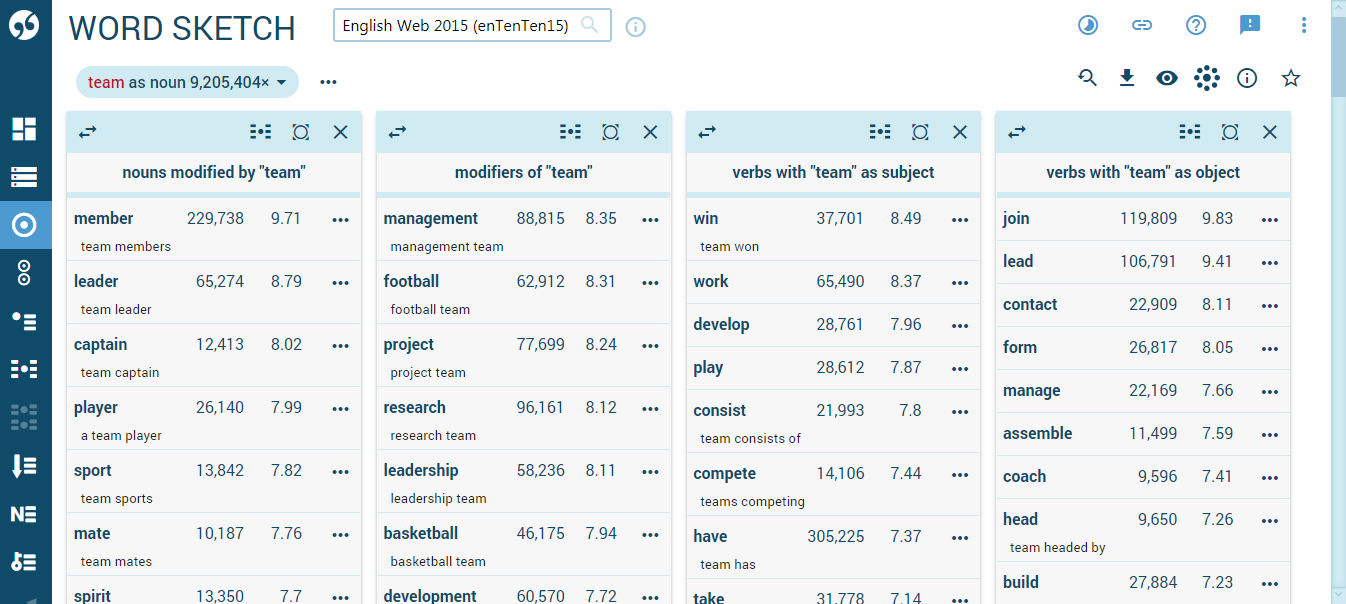
Large modern corpora can contain billions of words with thousands of instances of each word. This makes it unrealistic to look at each concordance line. The word sketch solves this problem. Words surrounding the search word are processed by the word sketch and displayed in a compact, easy to understand format and organized from the most typical to the least typical collocations. The following word sketch was generated from over 9 million instances of the word team. It shows the search word, its frequency, its collocates sorted into grammatical relations, the frequency of each collocate, typicality score, the most frequent representation of each collocation and a local menu with links to other tools.
Display this word sketch in Sketch Engine (login required)
Display a similar word sketch in an open corpus (no login required)
Working with the columns
For practicality, use the icons in the header of each column to reorder, close and display the columns again. Use the icons next to each collocate or in the header of the column to display the collocates in context as a concordance. To focus on only one column, use the icon which will hide all the remaining columns with one click. Hover the mouse over the icons to display tooltips which explain their functions.
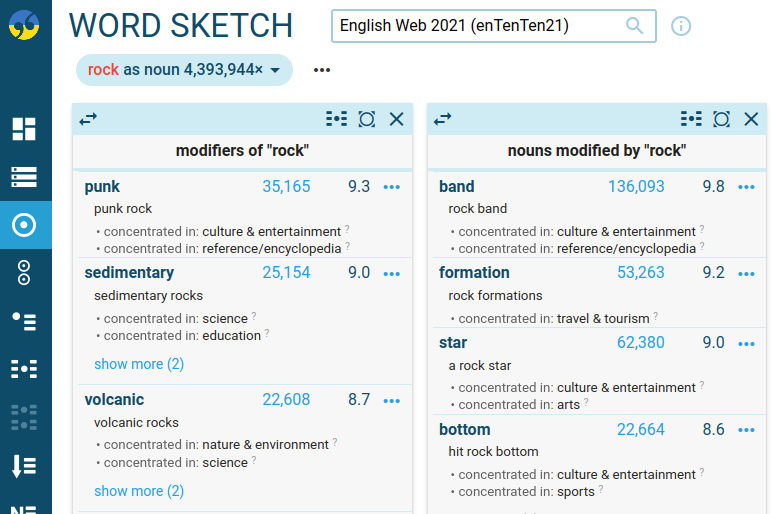
Displaying text types with a notable presence of the collocation
If there are text types the collocation is specific to, they can be displayed in the view options → show text types*. The maximum number of various text types can be set up. There are three labels that correspond to the following conditions:
- only in – if more than 97% of the occurrences appear in this text type;
- usually in – if more than 70% of the occurrences appear in this text type;
- concentrated in – if the collocation is represented very densely (= the relative frequency is high) in this text type.
The aforementioned conditions apply only if the specific text type is not a dominant one (i.e. it covers less than 50% of the corpus).
Read this paper for detailed information
* Displaying text types in Word Sketches is only possible if the corpus is set up that way. WSTTATTRS configuration should be included in the configuration file with the respective text types. If you needed help with the settings, please contact us at support@sketchengine.eu
Sorted by the score (typicality)
By default, the word sketch is sorted with the most typical collocations at the top. This is the preferred option for most uses because what is frequent is usually not interesting or useful, but typical is. The logDice score is used for determining how typical (or how strong) the collocation is. Use view options to display the score.
A high score means that the collocate is often found together with the node and at the same time there are not very many other nodes that the collocate combines with or it does not combine with them too frequently. The bond between the node and the collocate is very strong ⇢ strong collocation.
A low score means that the collocate likes to combine with very many other words. The bond between the node and the collocate is weak ⇢ weak collocation.
It is not possible to set a universal threshold between weak and strong collocations because each word behaves differently. The main purpose of the score is to sort the collocates by their typicality or strength, not to decide whether a collocation is weak or strong.
The view options allow sorting by frequency if needed.
How is the score computed
Please refer to Statistics used in Sketch Engine and to Lexicographer-friendly score for the formula. Here is a simplified but sufficiently informative explanation.
Referring to the screenshot above, to determine the strength of the collocation management team compared to other collocations of team, all nouns modified by management are found first. The sketch grammar for English determines which nouns surrounding management should be regarded as the modified nouns.
Then, each time management modifying team is found, management gets a plus point. Each time management is found modifying another noun, management is given a minus point. The logDice score is calculated to indicate whether there were many plus points or many minus points. The score is always presented as a positive number.
Interpreting the score
A very high score of the collocate means that there is little competition from other collocates. The node (the search word, the keyword) does not often combine with other collocates. In other words, the competitors are not frequent for either of these reasons or their combination:
- The number of different competing collocates is very small.
- The number of different competing collocates may be high but the frequency of each of them is low so the total stays low.
A very low score means that there is extreme competition from other collocates for either of these reasons or their combination:
- The number of different competing collocates is very high.
- The number of different competing collocates may be small but the frequency of each of them is extremely high which produces lots of competition for the collocate in question.
As a result, it is quite common that the most common and frequent words (new, go, be, small, very) hardly ever receive high scores as collocates because they are used so often in combination with so many other words that there is lots of competition. Exceptions can exist if the collocation is so extremely frequent and that it beats all its competitors.
Sketch grammar
The sketch grammar is a set of rules written in CQL which make use of POS tags and regular expressions to define which tokens should be included in each grammatical relation. For example, a subject may be defined as a noun before verb but the actual rule is much more complex defining more specific requirements for both the noun and verb, their relative position and compulsory and optional words between them.
The word sketch does not use any parsing information and a parsed corpus is not needed. However, sketch grammars using parsed corpora can be developed.
Instead of using the sketch grammars developed by Sketch Engine, users can develop their own and apply them to their own corpora but not to the preloaded corpora.
Requirements for the word sketch to work well
POS Tags and lemmas
The word sketch works with a POS-tagged and lemmatized corpus. Parsed corpus is not needed. Universal word sketches are available for corpora without tagging and/or lemmatization, see below.
The corpus has to be tagged in Sketch Engine or with the same tagset as the one used by Sketch Engine so that the tags are the same as the ones used in the word sketch grammar. A custom word sketch grammar has to be used if the corpus is tagged with a different tagset.
A word sketch can also be generated from a non-lemmatized corpus in which case each word form will be treated independently. Thus, using English as an example, a different word sketch would be produced for goes and a different one for went. Such word sketches exist only for languages where lemmatization is not supported by Sketch Engine.
Corpus size
The corpus size itself does not affect the quality of the result, what matters is the absolute frequency of the word for which the word sketch should be generated. At least a few dozen occurrences are required. However, a minimum of a few hundred occurrences is required for a usable word sketch. To obtain a rich word sketch with lots of collocates, a few thousand occurrences are needed at least. The quality improves with each order of magnitude.
Universal sketch grammar
A so-called universal sketch grammar is used for corpora in languages where tagging and/or lemmatization is not available. The grammatical relations will be simplified to something like noun to the right, noun to the left, verb to the right, verb to the left, or even word to the right, word to the left. Although simplistic, they are a great help when working with large corpora and high-frequency verbs because data coming from thousands of occurrences can be reviewed quickly and easily.
Referencing word sketches
Work on word sketch
Semantic Word Sketches (presentation). Diana McCarthy, Adam Kilgarriff, Miloš Jakubíček and Siva Reddy (2015). InCorpus Linguistics (CL2015).
Finding Multiwords of More Than Two Words. Adam Kilgarriff, Pavel Rychlý, Vojtěch Kovář and Vít Baisa (2012). In Proceedings of the 15th EURALEX International Congress, Norway, pp. 693–700.
A Quantitative Evaluation of Word Sketches. Adam Kilgarriff, Vojtěch Kovář, Simon Krek, Irena Srdanovic and Carole Tiberius (2010). In Proceedings of the 14th EURALEX International Congress. The Netherlands, pp. 372–379.
Towards disambiguation of word sketches. Vít Baisa (2010). In Text, Speech and Dialogue. Germany, Berlin: Springer-Verlag, pp. 37–42.
Word sketch for individual languages
The articles relating to individual languages can be found in the Bibliography section (e.g. Arabic, Chinese, Polish, Japanese, etc).
Bilingual word sketches
Kovář, Vojtěch, Vít Baisa, and Miloš Jakubíček. Sketch Engine for bilingual lexicography. International Journal of Lexicography 29.3 (2016): 339-352.
Vít Baisa, Miloš Jakubíček, Adam Kilgarriff, Vojtěch Kovář and Pavel Rychlý. Bilingual Word Sketches: the translate Button. In Proceedings of the 16th EURALEX International Congress. Bolzano, Italy, 15–19 July 2014, pp. 505–513.
Adam Kilgarriff. Terminology finding, parallel corpora and bilingual word sketches in the Sketch Engine. In Proceedings ASLIB 35th Translating and the Computer Conference, London, May 2013, pp. 129–132.
Detailed Sketch Engine manual
THOMAS, James Edward (2015). Discovering English with Sketch Engine (DESkE), chapter 9 Word Sketches, pp. 161–176.
Read this blog post to learn more about how the difference between the most frequent and most typical collocations.
Multiword Sketch — collocations with phrases
The multiword sketch is an extension of the word sketch. It processes the left and right context of a phrase and identifies the collocates of each word in the phrase. The collocations are only extracted from sentences which contain the collocation (phrase) in question. In other words, the collocates only come from contexts where the collocation (phrase) is used. Contexts where the members of the phrase are used on their own are excluded. This makes it possible to only display collocates related to a particular word sense or subject.
The multi-word sketch can be accessed in two ways:
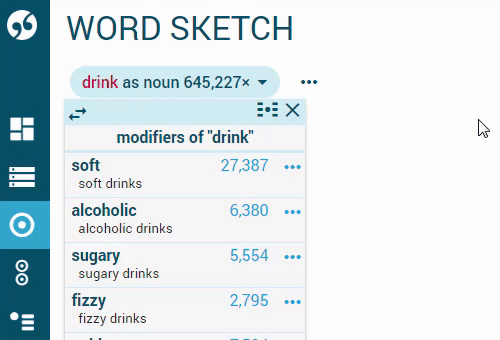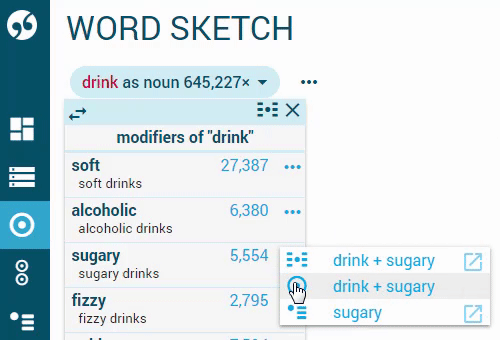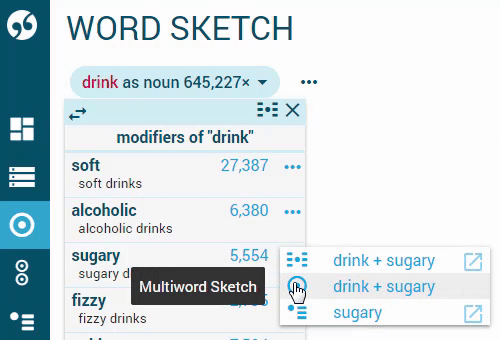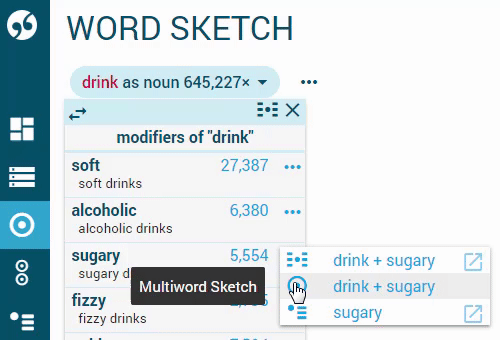
From the context menu
Locate the collocate you are interested in, click multiword sketch in the context menu.
By typing the collocation in the input form
Type the node and the collocate(s) directly in the input form. Their order is not important. Do not type words which are not a node or collocate(s), i.e. only words which would appear in the grammatical relations in the word sketch.
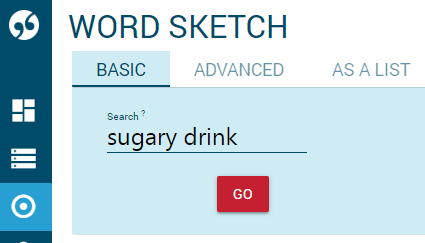
The input must only contain lemmas and only those that can be captured by grammatical relations, i.e. those that qualify as collocations. Typically, articles or other determiners and pronouns should not be included.
| to get collocations for | type |
| sweetened drinks | sweeten drink |
| grab a drink | grab drink |
Multiword sketch of sugary drink
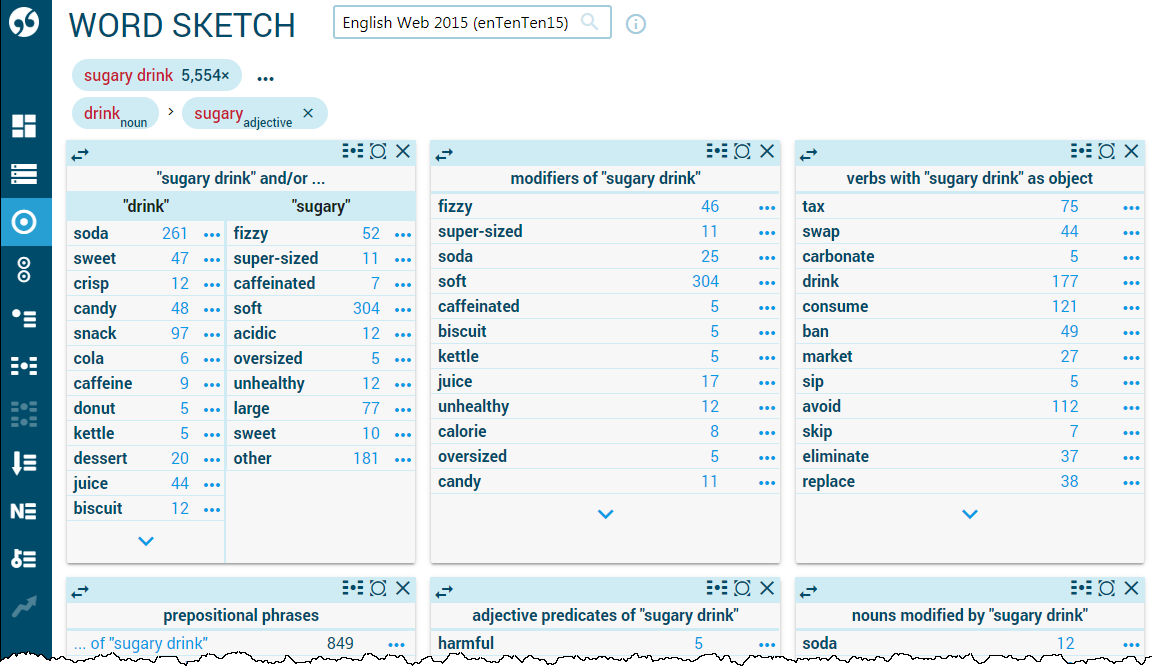
Bilingual Word Sketch — compare collocations in two languages
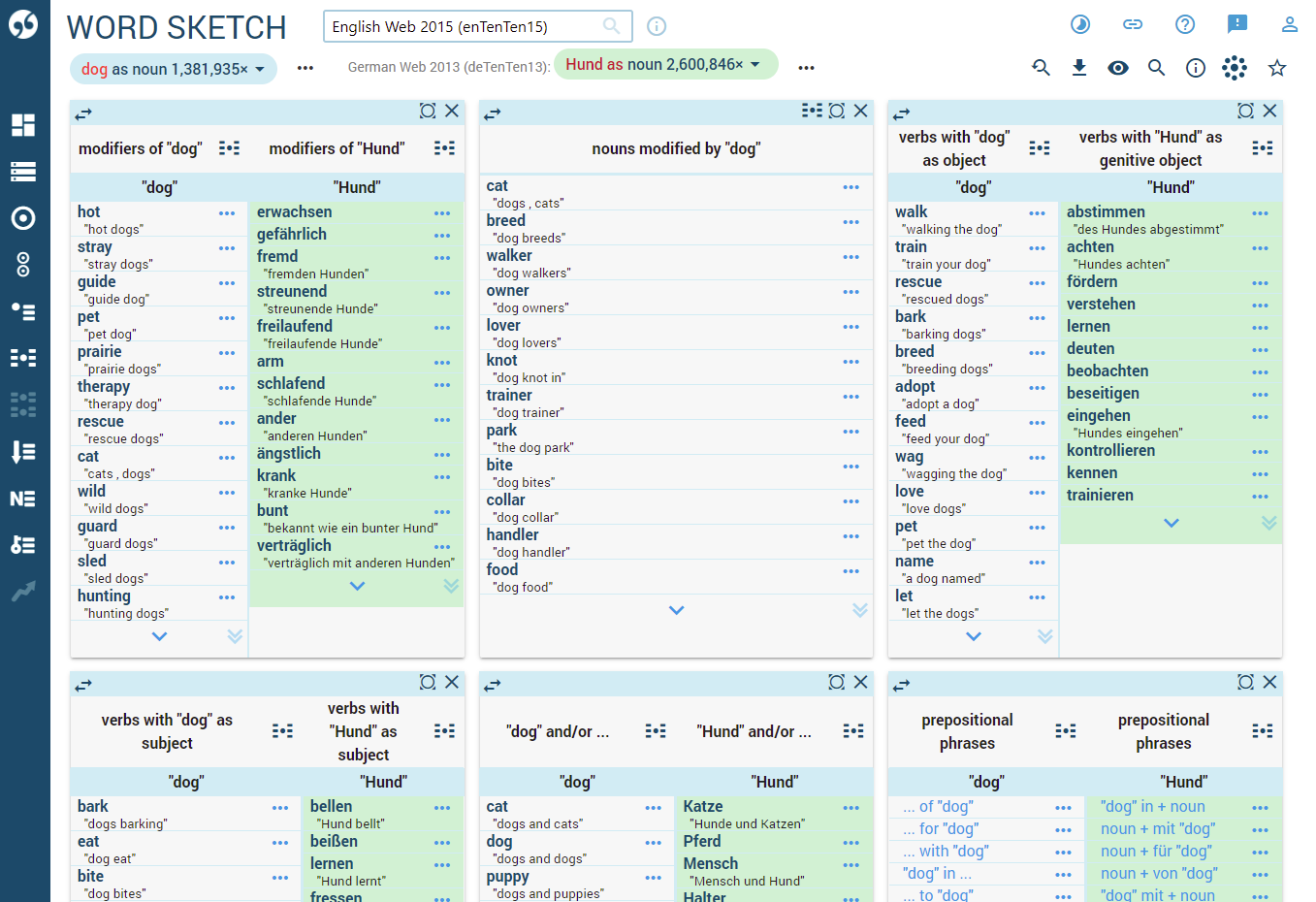
The bilingual word sketch displays a word sketch for the word and another word sketch for its translation side by side. This makes it easy to observe the collocations in both languages. This is the English – German multilingual word sketch for dog (Hund) using the English Web 2015 and German Web 2013 corpora.
The corresponding grammatical relations are aligned for easy comparison. Relations are not aligned if:
- The same (or comparable) grammatical relation is not included in the word sketch grammar for the language.
- The linguistic feature does not exist in both languages.
Statistics
Only monolingual statistics from the monolingual Sketch Engine can be displayed. Use the View options to display them. No multilingual statistics are available.
Corpora
This tool works with any corpora. A parallel corpus is not required.
How to use
- select the first corpus and go to Word Sketch
- select the ADVANCED tab
- tick Translate and select the corpus in the second language, type the lemma and, if needed, select the part of speech.
- click GO
Word Sketch as a List — combine all collocations into one column
The Word Sketch as a List tab combines all collocations and all grammatical relations into one list. to allow searching, comparing and analyzing all of them together. It is typically used to:
- sort all collocations by score or frequency irrespective of the grammatical relation
- find all collocations which have a common collocate (but a different node)
- find all collocations in one grammatical relation irrespective of the collocate and the node
- filter any of the above using starting with, ending with, containing or regex conditions.
The collocations are presented in the form of word sketch triples which consist of the node as lempos + name of grammatical relation + collocate as lempos, for example:
school-n modifiers of “%w” secondary-j
(to be understood as: secondary is a modifier of school)
Any conditions or filtering should be applied to the whole word sketch triple. For example, to list all collocations which are modifiers, the filter should be set as containing the word “modifier”)
This function may take several minutes on large corpora, especially on multi-billion-word corpora.
Sorting
The results can be sorted by raw frequency, relative frequency (frequency per million) or score.
Corpora
This tool works with any corpora.
How to use
- select the first corpus and go to Word Sketch
- select the AS A LIST tab
- select additional search parameters if needed
- click GO
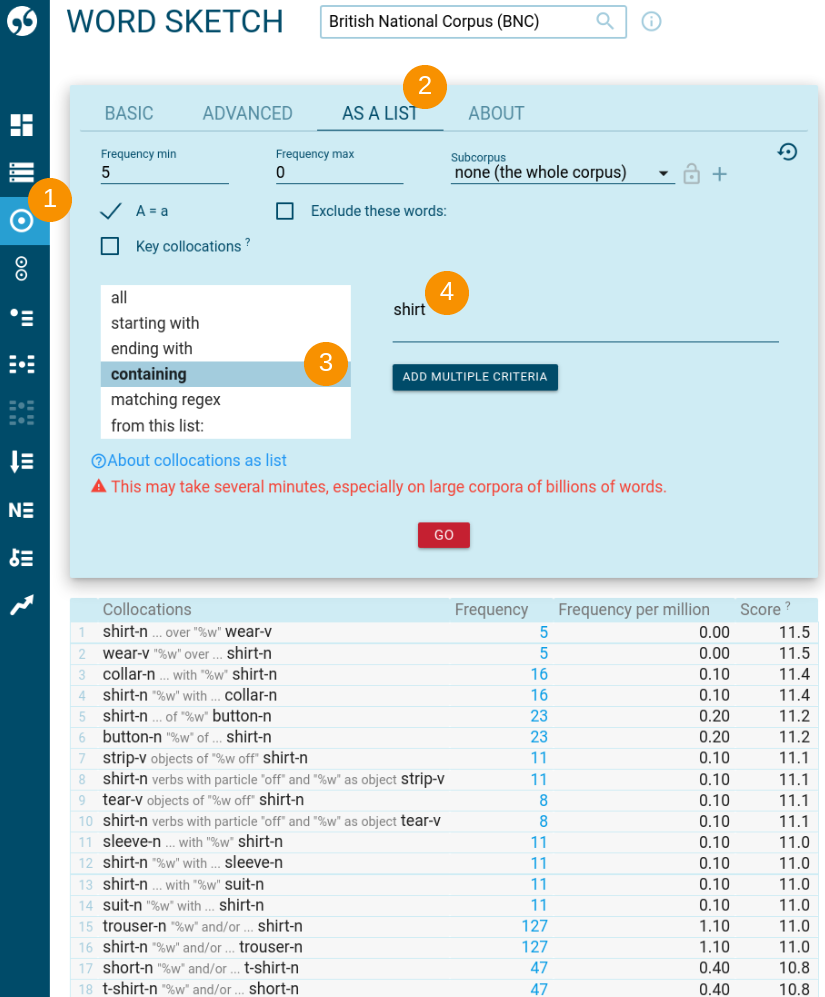
The screenshot shows that option containing find all collocations with “shirt” in the node or collocate position. This also includes words such as t-shirt or sweatshirt because the word “shirt” is a part of these words.
