amWaC: Amharic corpus from the web
The Amharic web corpus (amWaC) is an Amharic corpus made up of texts collected from the Internet. The corpus was prepared according to the standards described in the document A Corpus Factory for Many Languages (Kilgarriff et al. at LREC 2010).
Data was crawled by the SpiderLing web spider three times, in August 2013, October 2015, January 2016 and 2017 with a final size of almost 26 million words. Texts are in the Ge’ez script with matching SERA transliteration (The system for Ethiopic representation in ASCII).
Transliteration of selected Ge’ez characters into SERA system (Latin script).
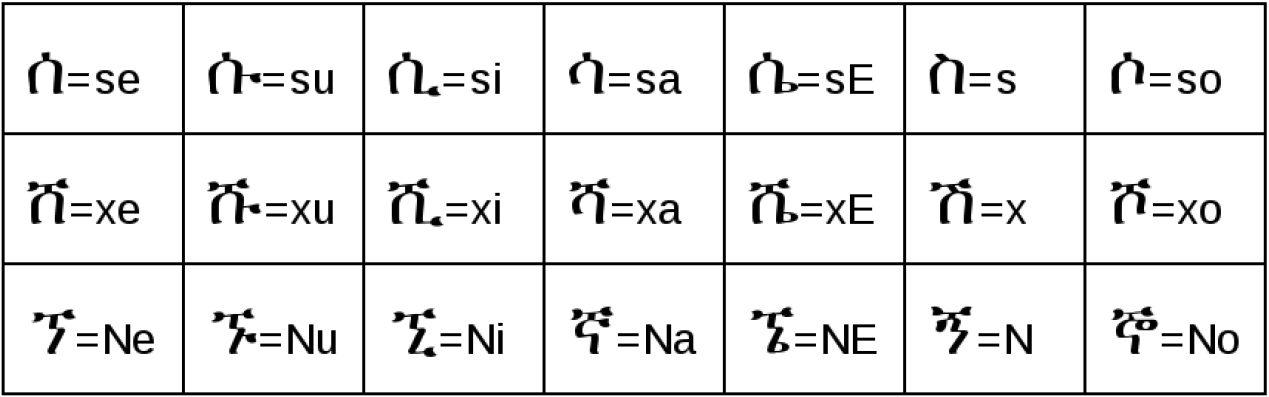
Document count – the most frequent web domains and domain size distribution:
| Top level domains | Web domains | Domain size distribution | |||
|---|---|---|---|---|---|
| com | 33,503 | gov.et | 21,224 | At least 1000 documents | 12 |
| et | 21,731 | blogspot.com | 10,328 | At least 500 documents | 6 |
| org | 18,631 | jw.org | 6,512 | At least 100 documents | 29 |
| net | 1,295 | addisadmassnews.com | 3,751 | At least 50 documents | 19 |
| va | 106 | wikipedia.org | 3,228 | At least 10 documents | 69 |
| others | 243 | ethiopiazare.com | 3,045 | At least 1 document | 202 |
The content of news/political and religious sites has a significant presence in the corpus sources.
The corpus was created in the framework of the HaBiT project (Harvesting big text data for under-resourced languages), see more on https://habit-project.eu/wiki/AmharicCorpus
Part-of-speech tagset
The AmharicWaC corpus was tagged with the TreeTagger based on manual annotation of Amharic 1065 news items containing 210,000 prosodic words. See the Amharic part-of-speech tag legend.
Tools to work with the Amharic corpus
A complete set of tools is available to work with this Amharic corpus to generate:
- word sketch – Amharic collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word units
- word lists – lists of Amharic nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- text type analysis – statistics of metadata in the corpus
Changelog
version 1 (21st April 2017)
- created word sketches
- added attribute “sera”
initial version (5th April 2017)
- size 17 million words
Bibliography
Amharic web corpus
Rychlý, P., & Suchomel, V. (2016, September). Annotated Amharic Corpora. In International Conference on Text, Speech, and Dialogue (pp. 295-302). Springer International Publishing.
Corpus factory method
Kilgarriff, A., Reddy, S., Pomikálek, J., & Avinesh, P. V. S. (2010, May). A corpus factory for many languages. In LREC.
Search the Amharic corpus
Sketch Engine offers a range of tools to work with this Amharic corpus.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extracting terms. Use our Quick Start Guide to learn it in minutes.
