Spoken BNC2014
The Spoken British National Corpus 2014 is a contemporary British English corpus made up of spoken British English in the 21st century. It Spoken BNC2014 corpus is only a 10-million-word part of the whole British National Corpus 2014 (currently not available in Sketch Engine yet) which contains 100 million words in total.
The Spoken BNC2014 corpus contains transcripts of recorded conversations, gathered from the UK public between 2012 and 2016. The conversations were recorded in informal settings and took place among friends and family members. The spoken BNC2014 is composed of 1,251 conversations of 672 speakers. The total size of British National Corpus 2014 spoken is 10.4 million words. The corpus has rich metadata (processed into text types in Sketch Engine) which can be used to restrict the analysis for calculating statistics.
The Spoken BNC2014 was developed in collaboration between Lancaster University and Cambridge University Press. More information can be found on the official website http://corpora.lancs.ac.uk/bnc2014/ and in Love, R., Dembry, C., Hardie, A., Brezina, V., & McEnery, T. (2017). The spoken BNC2014. International Journal of Corpus Linguistics, 22(3), 319-344.
Unlike the corpus on the official website, the Spoken British National Corpus 2014 in Sketch Engine was tagged by TreeTagger using Penn Treebank tagset with Sketch Engine modifications.
Tools to work with the British National corpus 2014
A complete set of tools is available to work with this spoken BNC2014 corpus to generate:
- word sketch – English collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word and multi-word units
- word lists – lists of English nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
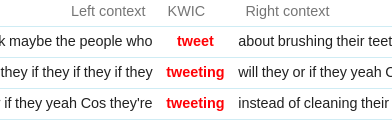
- concordance – examples in context
- trends – diachronic analysis automatically identifies neologisms and changes in use
Bibliography
Primary publications
The primary publication for the Spoken BNC2014 whose citation is required is:
-
Love, R., Dembry, C., Hardie, A., Brezina, V. and McEnery, T. (2017). The Spoken BNC2014: designing and building a spoken corpus of everyday conversations. In International Journal of Corpus Linguistics, 22(3): 319-344. DOI: 10.1075/ijcl.22.3.02lov
Other major publications from the BNC2014 team
McEnery, T. and Love, R. (2018). Bad Language. In Culpeper, J., Kerswill, P., Wodak, R., McEnery, T. and Katamba, F. (eds). English Language: Description, Variation and Context (2nd ed.). London: Palgrave.
Brezina, V., Love, R. and Aijmer, K. (eds). (2018). Corpus Approaches to Contemporary British Speech: Sociolinguistic studies of the Spoken BNC2014. New York: Routledge.
McEnery, T., Love, R. and Brezina, V. (eds). (2017). Compiling and analysing the Spoken British National Corpus 2014. International Journal of Corpus Linguistics 22(3) Special Issue. DOI: 10.1075/ijcl.22.3.

Search the British National Corpus 2014
Sketch Engine offers a range of tools to work with this English British National Corpus 2014.
or
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.
