A general purpose multilingual corpus available in Sketch Engine
The EUR-Lex parallel corpus is a collection of multilingual corpora in all the official languages of the European Union. The corpus has been built from HTML files available in EUR-Lex database that consists of European Union law and other public documents of the EU. Thanks to the coverage of a vast area of subjects, the corpus is an excellent general purpose resource for anyone looking for translation examples in many languages.
A substantial part of the documents is translated into all official languages of the European Union (currently 24). Languages which joined the EU later are represented by smaller corpora proportional to the length of their membership.
Structure of the EUR-Lex parallel corpus
Technically speaking, the documents are segmented and aligned on paragraph level. This means that the user can search for a matching paragraph containing the translation. The paragraphs are, however, fine-grained and usually correspond with sentences which means that the user is able to search for matching sentences or very short paragraphs.
Sketch Engine offers also the smaller corpus of judgments of the European Parliament, see more.
How to get the data
Academic institutions
The EUR-Lex corpus is released under CC-BY-NC-SA licence. Because of the file size, please email us at support@sketchengine.eu first and we will set up a temporary download link for you. Data are supplied as vertical text with an alignment file. The total size is 220 GB. For the original documents, see the official EUR‑Lex website.
For commercial use
Please contact us for a quote.
How to cite
Please, consider mentioning Lexical Computing in Acknowledgements and referring to the original paper (below) if you use EUR-Lex corpus.
Vít Baisa, Jan Michelfeit, Marek Medveď, Miloš Jakubíček: European Union Language Resources in Sketch Engine. In The Proceedings of tenth International Conference on Language Resources and Evaluation (LREC’16). European Language Resources Association (ELRA). Portorož, Slovenia. 2016.
Important copyright notice
© European Union, 1998-2016
Except where otherwise stated, reuse of the EUR-Lex data for commercial or non-commercial purposes is authorized provided the source is acknowledged (see above). The reuse policy of the European Commission is implemented by the Commission Decision of 12 December 2011. Some documents, like the International Accounting Standards, may be subject to special conditions of use, which are mentioned in the respective Official Journal. For all other copyright issues regarding EUR-Lex, please contact op-info-copyright@publications.europa.eu.
A list of metadata in EUR-Lex parallel corpus
- Author (institution or person) of document: an author who created the document
- CELLAR: a string storing in a single place all metadata and digital content managed by the Publications Office in a standardized way
- CELEX number: number composed of the number of the sector, then 4 digits for the year, then one or two letters for the type of document and finally 2-4 digits for the number of the document (e.g. 42011L0019 – 4 is the sector, legislation; 2011 is the year of publication in the OJ*; L represents EU directives and 0019 is the number under which the directives was published in the OJ)
- Date of document: specific date when the document was created
- Date of publication in Official Journal: specific date when the document was publicized in the Official Journal of the European Union
- Document category (CELEX sector): grouped more document types into one superior category
- Document title: a title of the document
- Document type: the main topic of the document, e.g. Financial Regulation Budget, etc.
- EuroVoc thesaurus term: a term from the EUROVOC THESAURUS TERM
- Last modification date: last date when the document was modified
- Year of document: year when the document was created
- Year of publication in Official Journal: year when the document was publicized in the Official Journal of the European Union
* the Official Journal of the European Union
Source documents of EUR-Lex parallel corpus
See all types of documents available in the corpus at http://eur-lex.europa.eu/content/tools/TableOfSectors/types_of_documents_in_eurlex.html?locale=en
1) the Official Journal of the European Union,
2) EU law (EU treaties, directives, regulations, decisions, consolidated legislation, etc.),
3) preparatory acts (legislative proposals, reports, green and white papers, etc.),
4) EU caselaw (judgments, orders, etc.),
5) international agreements,
6) EFTA documents and
7) other public documents dating back to 1950s in 24 official EU languages.
Search the EUR-Lex parallel corpus
Sketch Engine offers a range of tools to work with this EUR-Lex parallel corpus.
EUR-Lex
number of aligned structures
The table shows the number of aligned structures (paragraphs in the case of EUR-Lex) for each pair of languages. In millions, click to enlarge.
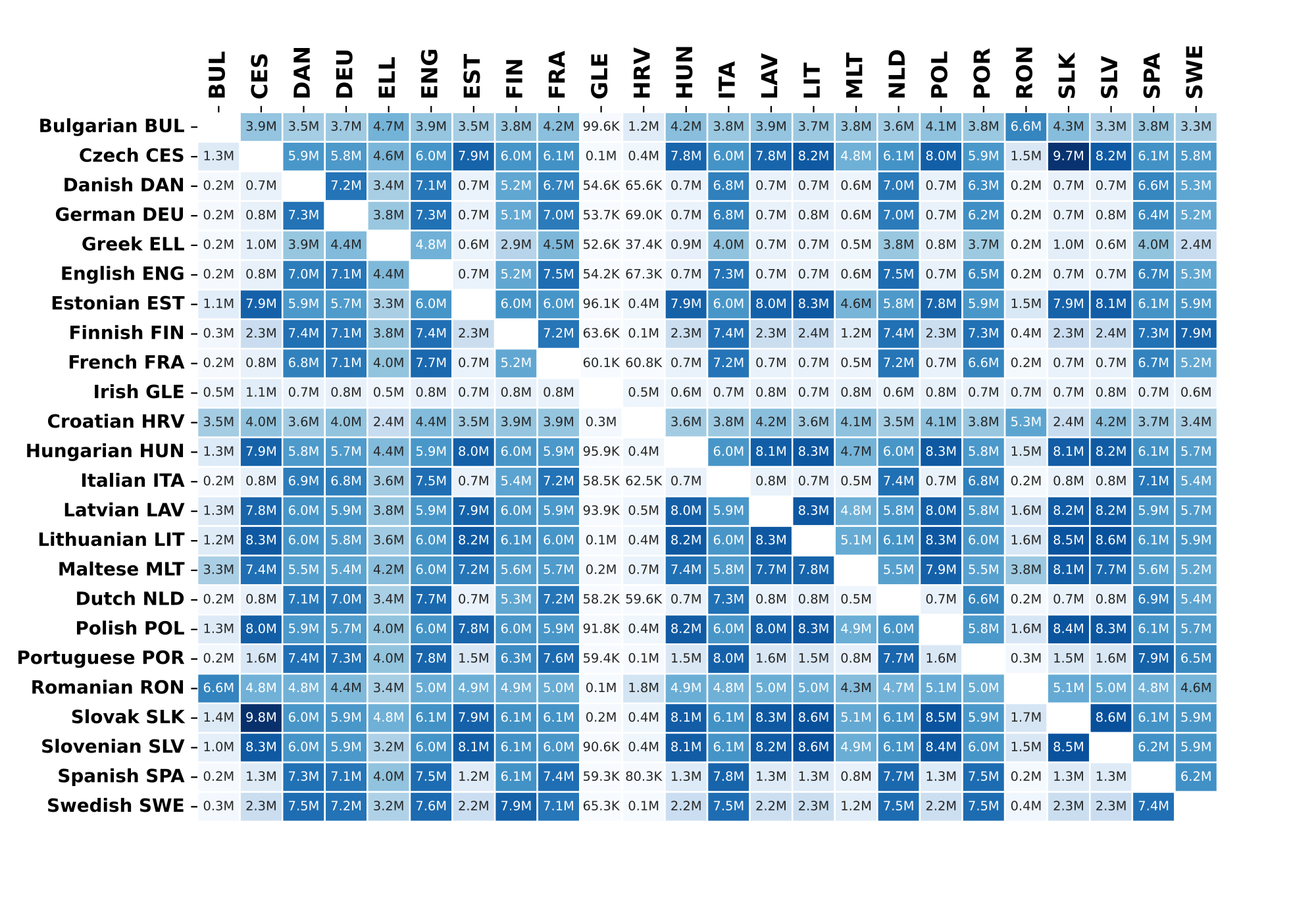
Size in tokens
Enlarge the image by clicking on it.
To read the size, find the language of interest along the vertical axis on the left and find it’s intersection with the second language listed along the horizontal axis. The number gives the size of the first language.
Example: (looking at the first line) The corpus contains 213 million words of Bulgarian which are translated into Czech, 150.4 million words of Bulgarian translated into Danish etc. It contains 206.6 words of Czech translated into Bulgarian and 139.3 million words of Danish translated into Bulgarian.

Tip
Learn to work with multilingual and parallel corpora in Sketch Engine. Refer to the user guide.
Use Sketch Engine in minutes
Generating collocations, frequency lists, examples in contexts, n-grams or extracting terms is easy with Sketch Engine. Use our Quick Start Guide to learn it in minutes.
