Related pages in documentation
IMPORTANT: If you want to make the changes described on this page, please contact the support at support@sketchengine.eu
What are corpus configuration options?
Corpus configuration options are stored in a corpus configuration file (also called a registry file) and contain basic information about a corpus, such as the corpus name, path to the vertical file, encoding information, used attributes, etc.
Note: information “manatee [number]” indicates from which version of manatee (software used in Sketch Engine for searching in text corpora) the given option is available
NAME
name of the corpus; defaults to the corpus config filename
ENCODING
corpus encoding
DEFAULTLOCALE
default LOCALE for attributes (see below). Defaults to standard POSIX locale (C). Can be set using LANGUAGE instead.
LANGUAGE
language name – it should be capitalized and one of the allowed names, otherwise the system will not be able to automatically detect the right locale and you may experience errors when sorting or regular expression matching of non-ASCII characters.
NOLETTERCASE
for corpora of languages that do not have capital letters, e.g. Arabic, Chinese, Japanese, Korean, Nepali, Telugu, Tamil, …
For example, in the case of an Arabic corpus, the registry file should contain the following configuration (it implies that lowercase attributes are not required such as lc or lemma_lc):
NOLETTERCASE "1"
RIGHTTOLEFT
indicates whether the language of the corpus is in the right-to-left script (e.g. Arabic)
ALIGNED
for parallel corpora only: comma-separated list of aligned corpora. All corpora should have a structure defined in ALIGNSTRUCT (“align” in manatee 2.67 and higher).
ALIGNSTRUCT
[since manatee 2.67]
for parallel corpora only: the name of the mapping structure, i.e. such a structure that is present in both parallel corpora and on which the alignment is performed. Defaults to “align”.
ALIGNDEF
[since manatee 2.67]
for parallel corpora only: comma-separated list of mapping definition files to aligned corpora.
NEWVERSION
for old versions of corpora only: the name of the new version of the corpus
DEFAULTATTR
default attribute for CQL query evaluation. It is also used to map attribute alias “-” in the web API.
MAINTAINER
identification of the person responsible for maintaining the corpus
DOCSTRUCTURE
the structure that should be considered to be a document, defaults to “doc”.
NONWORDRE
a regular expression determining which tokens should not be considered words, defaults to [^[:alpha:]].* – therefore the default definition of a word is [[:alpha:]].*.
WSTRANSLATE
configuration of languages and corpora for bilingual word sketch using the “Translate button”.
For example:
WSTRANSLATE ",French,frtenten,German,detenten2_simplews,Polish,pltenten,Spanish,eseutenten11_freeling,Italian,ittenten"
Appropriate dictionaries named - are expected in pcdict_path (/corpora/pcdicts or as specified in run.cgi).
DIACHRONIC
to set a structure attribute containing a date for computing trends. Values must be in the numeral format, e.g. 2016/01 where still the same delimiters (e.g. /) always are in the same places
DEFFILTERLINK
link for the concordance results to the word sketch relation “definitions”. The value is 1. (usually)
Location features
GDEXDEFAULTCONF
path to the default GDEX configuration for the given corpus (used only if GDEX is installed)
INFO
arbitrary corpus information like source, size etc. There is no automatic processing of this data. If the value begins with the “@” character the rest is taken as a full path of a file containing INFO data
INFOHREF
link to arbitrary documentation on the web
ERRSETDOC
link to a list of error codes, should be used only in case of learner corpora (error-annotated)
PATH
full path of the corpus home directory which contains all data files
REFCORPUS
reference corpus for CQL thesaurus queries
SUBCDEF
path for the subcorpus definition file. See Subcorpus config documentation. A subcorpus definition file allows you to share subcorpora with all users of the corpus
SUBCBASE
path for global subcorpora, default PATH/subcorp
TAGSETDOC
URL of the tagset documentation, so users can quickly refer to it from a button next to the CQL box in the search interface. If absent, the button does not appear in the interface
TERMBASE
path to compiled term data files, defaults to PATH/terms (prefix)
TERMDEF
path to term grammar definition file
URLTEMPLATE
path to media type, for instance:
STRUCTURE s {
ATTRIBUTE audio {
URLTEMPLATE "https://YOUR_MEDIA_FILES_URL_PREFIX.com/%s"
MEDIATYPE "audio"
}
}
and then in the corpus, you should have the following structure:
< s audio="somefile.wav" > This is a sentence in the corpus. < /s >
The possible MEDIATYPE are: audio, image, video.
VERTICAL
full path of the source vertical text(s), it is used only by “encodevert” program, if the value starts with “|” the rest is treated as a shell command, and the vertical text will be taken from the standard output of the command, e.g.
VERTICAL "| xzcat /path/to/vertical/english-vertical{01..10}.vert.xz"
when VERTICAL is created by 10 compressed archives, they will always be used in the same order; the order of tokens cannot be changed during recompilation. It is strongly recommended not to use the * (asterisk) wildcard, as it does not guarantee that multiple files are always processed in the same order.
WSBASE
path to compiled word sketches data files (including WS highlights), defaults to PATH/WSATTR-ws (prefix), use “none” to disable the Word Sketch feature entirely
WSDEF
path to the word sketches grammar definition file
(WSOLDSCORES)
use old scores, obsolete computation of word sketch scores; do not use this setting
WSHIST
path to the file with a word highlights definition used for the Find X tool (formerly called “histograms”)
WSTHES
path to word sketches thesaurus data files, defaults to PATH/WSATTR-thes
Structures and Attributes
ATTRIBUTE
This provides the definition of a positional attribute. At least one positional attribute should be defined. The first defined attribute is the default one (in most cases it is the word form and the name of this attribute is “word”). The order is important: the nth ATTRIBUTE in the corpus config file provides a name for the contents of the nth column in the vertical file. Some features of SkE require attributes called ‘tag’, ‘lemma’, ‘lempos’, ‘lc’. The order of attributes is not important, it is used only during the initial encoding and to display the list of attributes in the concordance “View options” form. Attribute names must start with an alphabetic character or underscore and subsequent characters must be alphanumerical (including underscore). i.e. (‘a’..’z’|’A’..’Z’|’_’)(‘a’..’z’|’A’..’Z’|’0′..’9’|’_’)*
STRUCTURE
This provides the definition of a structural tag. Structures can themselves have attributes (structural attributes as opposed to the positional attribute described above). Structure names must start with an alphabetic character or underscore and subsequent characters must be alphanumerical (including underscore). i.e. the same criteria as ATTRIBUTE names above.
ATTRIBUTES (both positional and STRUCTURE ones) can be repeated and customized using additional options, such as:
- LOCALE
Locale code of a used language (and region), this value is used in the query evaluation (of regular expressions) and the concordance line sorting. Defaults to the value of DEFAULTLOCALE (set explicitly or using LANGUAGE.)
- MULTIVALUE
Indicates whether the attribute value consists of multiple parts separated by MULTISEP. The parts will be inserted into the lexicon in addition to the entire value.
- DEFAULTVALUE
Default value for the attribute value if no value is present in the source vertical
[since manatee 2.30] if not overridden by this configuration option, the default DEFAULTVALUE is set to “===NONE===”.
- MULTISEP
Defines a single-byte multivalue separator, if empty (“”), the attribute value is split into characters.
- HIERARCHICAL
States that the attribute should be treated as hierarchical. Its value is the separator of the fields in the hierarchy (can be any string). For structural attributes (header fields) only. The hierarchical headers need to be specified as MULTIVALUE in the corpus config file. An example of a hierarchical attribute definition in the corpus configuration file (see more here):
STRUCTURE doc {
ATTRIBUTE domain {
MULTIVALUE "1"
MULTISEP ","
HIERARCHICAL "::"
}
}
- ATTRDOC
Additional information for structure attributes. In the case of preloaded corpora or Sketch Engine local installation, there can be an interlink referring to a file on the server whose content will be displayed in the interface instead of the link itself.
- ATTRDOCLABEL (deprecated now)
Display name for the ATTRDOC link.
- NUMERIC 1
Indicates that attribute values will be sorted according to their numeric value. For structural attributes (header fields) only.
Advanced topics on attributes and structures, see below.
Controlling display in concordances
SHORTREF
the attribute of a structure to display as a default reference in the left-hand column of a concordance. Defaults to the first attribute of the first structure or “#” (token number) if no attribute of a structure exists. The syntax is SHORTREF “=structure.attribute”, e.g. “=doc.id” for displaying only the value of “doc.id” or SHORTREF “structure.attribute” (without equal sign) for displaying the pair “structure.attribute=value”. There can be multiple links in SHORTREF, e.g. SHORTREF “=bncdoc.id,#,bncdoc.year” has a reference “J0P,#507890,bncdoc.year=1977”. (This adds also the link Doc Id to the left-hand menu.)
SIMPLEQUERY
template for the CQL query that is created from the simple query. Defaults to [lc=”%s” | lemma_lc=”%s”] (if the *lc attributes are present), otherwise [word=”%s” | lemma=”%s”] if word and lemma are present, and [word=”%s”] if only word is present. Any CQL query template can be used. The string “%s” is replaced by the actual content of the simple query field.
STRUCTATTRLIST
comma-separated list of references that will be used to determine the References list in view options. Defaults to all attributes of the structures specified in the config file.
DEFAULTSTRUCTS
comma-separated list of structures that will be displayed in the concordance by default. The sentence structure is always displayed.
DEFAULTSTRUCTS "doc,text"This will display the structures doc and texts in the concordance results (the sentence structure is automatically turned on). Users can change this setting via View options. The changes are stored per particular user and corpus.
FREQTTATTRS
comma-separated list of structure attributes that will be used for Frequency -> Text types in the concordance view. Defaults to SUBCORPATTRS.
FULLREF
comma-separated list of references which will be displayed as a full reference at the bottom of the window when the user clicks on the SHORTREF for a concordance line. Defaults to the value of STRUCTATTRLIST.
HARDCUT
maximum number of query result lines in query evaluation, default=0 meaning no limit
MAXKWIC
[since Manatee 2.107]
maximum number of positions in the KWIC of a concordance, default=100 (if you want unlimited KWIC use MAXKWIC=0)
MAXCONTEXT
maximum number of positions in context for displaying and saving concordance, default is 100 to both sides which means the limit of 300 positions (100 left + 100 KWIC + 100 right). If you want unlimited context use
MAXCONTEXT "0"MAXDETAIL
maximum number of positions in the detail view (at the bottom of conc view), default=MAXCONTEXT
MEDIATYPE
a type of embedded media, you can use one of the following values: audio, video, image, unknown, e.g.
STRUCTURE s {
ATTRIBUTE audio {
URLTEMPLATE "https://YOUR_MEDIA_FILES_URL_PREFIX.com/%s"
MEDIATYPE "audio"
}
}
STRUCTCTX
display the whole structure in the detail view (at the bottom of conc view)
WRAPDETAIL
name of the structure that will cause line wrap in the detail context window (new in bonito 2.76), default none
Attributes of structures
In an additional information block of a STRUCTURE option there can be arbitrary many ATTRIBUTE options (with possible additional option blocks), which can include the following:
LABEL
label used in references instead of the name of ATTRIBUTE, for example
STRUCTURE doc {
ATTRIBUTE tld {
LABEL "Top level domain"
...
}
}
DISPLAYTAG
if “1” (by default) it displays an XML tags like
< s>, < s/>
in concordances; set it to “0” not to display a tag, use other DISPLAY… options to modify concordance output
DISPLAYBEGIN
If the attribute DISPLAYTAG has a value “0”, it is allowed to replace the default XML tag with a different character or characters. DISPLAYBEGIN sets a starting tag of the structure, e.g.
< s >
can be changed to
|s|
by the following configuration:
STRUCTURE s {
DISPLAYTAG 0
DISPLAYBEGIN "|s|"
}
A special value “_EMPTY_” means that nothing is displayed. This value is usually used for a special structure glue
< g/ >
See this example:
STRUCTURE g {
DISPLAYTAG 0
DISPLAYBEGIN "_EMPTY_"
}
[since manatee 2.28] structure attributes can be displayed using the %(attribute_name) syntax, e.g. if you’d like the structure to be marked by the text “STR-” concatenated with the id attribute of structure str, use the following syntax:
STRUCTURE str {
ATTRIBUTE id
DISPLAYTAG 0
DISPLAYBEGIN "STR-%(id)"
}
DISPLAYEND
same as DISPLAYBEGIN only for the end tag
DISPLAYCLASS
This attribute can be used to change color of any structure in Concordance. It might be useful in corpora that are used for analysing learners’ grammar mistakes. Such a grammar mistake might use a special structure and then DISPLAYCLASS will be used inside this structure to set the color. In the following example “concred” is used as an argument and it means the color will be red. A hexadecimal value is also supported, e.g. “#FF0000”.
STRUCTURE err {
ATTRIBUTE type {
LABEL "Error"
}
DISPLAYTAG 0
DISPLAYBEGIN "[%(type)]"
DISPLAYEND "|"
DISPLAYCLASS "concred"
NESTED 1
}
A screenshot from a corpus “English Wikipedia sample with Error annotations”, where different colors (red, green) are used to differentiate between good and bad language usage.
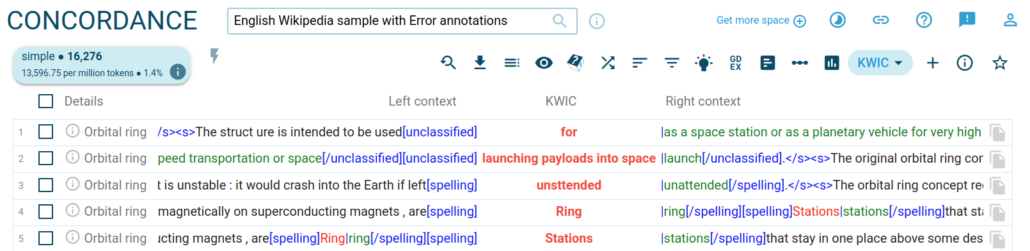
MAXLISTSIZE
in text types, if an attribute has more than 22 possible options, an input text field with autolookup is offered to user rather than a list of checkboxes. MAXLISTSIZE can change the default value. Example:
STRUCTURE document {
ATTRIBUTE id
ATTRIBUTE domain {
MAXLISTSIZE "30"
}
}
NESTED
Enables nested structures. Note that nested structures may not be supported in all functions and in some cases they may cause a mismatch in frequency figures. They are primarily designed to enable nested error annotation in learner corpora. Nesting is limited to a depth of 100 levels and deep (> 10 levels) nesting may have a noticeable negative performance impact. Generally, it should be avoided if possible by defining a structure for each level of nesting, e.g. section, subsection, subsubsection etc.
STRUCTURE err {
NESTED 1
}
STARATTR
to set a structure attribute for which the average value will be counted. This value can be displayed in the concordance results and word sketch results.
For example, a text corpus has the structure attribute “review” containing ratings (on a scale of 1 to 5) for each document. Then the STARATTR configuration for this attribute “review” counts the average value of the ratings of each document where the search token occurs. If the word XYZ occurs in 3 documents with the ratings 2, 3 and 4, the STARATTR configuration returns the number “3” and the word XYZ will have this value in concordance and word sketch results.
STRUCTURE doc {
ATTRIBUTE review
}
STARATTR review
Controlling Text Types (concordance form and subcorpus creation)
SUBCORPATTRS
Comma-separated list of structure attributes displayed in the query form and in frequency by text types, if FREQTTATTRS is not set. It also determines attributes available for creating subcorpora in the user interface. Use “|” instead of comma to display attributes on the same row in the subcorpus creation form. Use “|*” instead of a comma to put the next attribute right under the previous attribute (rather than on a new line — introduced in bonito 3.90) Example:
SUBCORPATTRS "bncdoc.alltyp|bncdoc.alltim|*bncdoc.id,bncdoc.wridom|bncdoc.wrimed"
— subcorp form contains 2 rows:
1: alltyp and alltim+id 2: wridom and wrimed
If SUBCORPATTRS is not defined, all attributes will be shown in the ‘Text Type’ part of the concordance form (usually not the desired outcome)
Word classes and lemmas
BIDICTATTR
option for computing bilingual dictionary. If this attribute is empty, it is tested whether the actual corpus contains one of these attributes in the following order: lemma_lc, lemma, lc, word.
DIAPOSATTRS
[since manatee 2.204]
This option is used for the specification of a list of positional attributes for which trends (diachronic analysis tool) will be calculated.
value: comma-separated positional attributes. By default (if DIAPOSATTRS is not presented), trends are calculated for all positional attributes available in the corpus. For instance, if you need to compute trends only for attributes word and lemma:
DIAPOSATTRS "word,lemma"
WPOSLIST
This list is used to display user-friendly names of parts of speech in these locations:
- the input from of Concordance–Advanced–Filter
- CQL builder–Insert common tags
- the list of common tags on the corpus info page
The list maps regular expressions to the POS user-friendly names. The first character in the string indicates the separator used in the rest of the string. An example for TreeTagger English tagset (modified version of Penn tagset):
WPOSLIST ",adjective,JJ.?,adverb,RB.?.,conjunction,CC,determiner,DT,noun,N.*,noun singular,NN,noun plural,NNS,preposition,IN,pronoun,PP,verb,V..?|MD"
LPOSLIST
This list maps lempos suffixes to their user-friendly names. The names appear in these input forms: Wordlist–Advanced and Concordance–Advanced. The first character in the string indicates the separator used in the rest of the string.
Example from BNC:
LPOSLIST ",adjective,-j,adverb,-a,conjunction,-c,noun,-n,preposition,-p,pronoun,-d,verb,-v"
WSPOSLIST
This is deprecated since bonito 3.90 — directive *WSPOSLIST in sketch grammar should be used instead.
This list maps lempos suffixes to their user-friendly names. It is used in these input forms: Word Sketch, Thesaurus. It has the same syntax as LPOSLIST.
WSATTR
attribute name for which word sketches are computed, defaults to “lempos” if the corpus has that attribute, or “lemma” if the corpus has that attribute, or DEFAULTATTR otherwise
WSSTRIP
number of characters to strip from the end of a word in a word sketch listing, defaults to 2 if WSATTR is “lempos”, or 0 otherwise. (It means that you need to explicitly use this option with the value “2” when the word sketch attribute is wordpos.)
WSDIFFSTEP
minimum difference of WS scores to highlight in different colors
WSMINHITS
minimum frequency for a candidate of word sketches, default value is “0”, it is suitable for filtering nonsignificant relations (e.g. spam, mistakes) and also for faster computing of word sketches in large corpora
WSTTATTRS
text types for which the word highlights (Find X tool) are computed. Any changes in WSATTATTRS require corpus recompilation with --recompile-lcm
Dynamic attributes
Dynamic attributes are positional or structure attributes that are not present in the source vertical text, but are derived automatically from another attribute (which may also be dynamic). As such, they represent a shorthand for adding derived attributes without the need to put them into the source vertical file and without the need to recompile the whole corpus. Dynamic attributes also occupy less disk space while being only marginally slower for querying if you use the “index” DYNTYPE.
An example of a dynamic attribute that you can find in many corpora in Sketch Engine is lc, which stands for lowercase word form, and lemma_lc, which stands for lowercase lemma. They are derived from the word and lemma attributes by applying a built-in lowercase dynamic function. You should always add them to your corpus configuration file unless you change the SIMPLEQUERY specification of simple search not to use them, because otherwise the search is going to fall back on regular expressions to achieve case-insensitive search, which is slower by orders of magnitude.
Sketch Engine contains several built-in dynamic functions that allow primitive string manipulation (such as stripping parts of a string), and you can quite easily add your own new ones (see DYNLIB). Dynamic attributes are created when the corpus is compiled using encodevert. If you want to set up additional dynamic attributes or, after you have changed a dynamic attribute, it is not necessary to recompile the whole corpus. Just adjust the configuration file and create the dynamic attributes using mkdynattr:
mkdynattr
DYNAMIC
if this option exists, the attribute is a dynamic one, and the value of this option is the name of the C function that defines the string transformation or the path to the shell script if DYNLIB is set to “pipe”. The example below shows the dynamic attribute “lemma” derived from another attribute “lempos” by stripping the last two characters (so that intend-v maps to intend).
ATTRIBUTE lemma {
DYNAMIC striplastn
DYNLIB internal
ARG1 "2"
FUNTYPE i
FROMATTR lempos
TYPE index
}
DYNLIB
The dynamic library containing the desired function selected by DYNAMIC. This can be either set to “internal” to use the builtin functions, “pipe” to provide your own shell script or to an absolute path of a dynamic library (.so shared object as defined by your POSIX system) that will be loaded automatically.
FUNTYPE
type of given function
- 0 – no extra argument
- c – one char extra argument
- s – one (const char*) extra argument
- i – one int extra argument
- cc – two char extra arguments
- ii – two int extra arguments
- ss – two (const char*) extra arguments
- ci – two extra arguments, first char, second int
- cs, sc, si, ic, is – likewise
ARG1
the first optional fixed parameter
ARG2
the second optional fixed parameter
FROMATTR
the name of the attribute from which the dynamic attribute is created
DYNTYPE
type of the dynamic attribute, possible values are “plain”, “lexicon”, “index” and “freq”
- plain – only displaying is enabled
- lexicon – displaying and counting (frequency distribution) are enabled
- index – all features, including querying, are enabled
- freq – like index, but with frequencies for each attribute value being precompiled. This should be used for cases where many source attribute values map to a single target (dynamic) attribute value (e.g., URL to top-level domain name), and recomputing frequencies from source attributes may take a long time. Unless you have significant disk-space constraints, you should choose this option, which provides the best performance.
TRANSQUERY
use transformation function for queries (multivalues not supported). Example:
ATTRIBUTE lc {
DYNAMIC lowercase
DYNLIB internal
ARG1 "C"
FUNTYPE s
FROMATTR word
DYNTYPE index
TRANSQUERY yes
}
This means that, for query [lc=”Test”] we apply the function “lowercase” to the argument “Test” to search for “test”; without TRANSQUERY, we would search for “Test” and find nothing. (This configuration affects only the query itself, not the stored index during the compilation.)
MAPTO
maps one positional attribute into another, which is especially useful, e.g., for querying thesaurus using wordforms.
ATTRIBUTE word {
MAPTO lempos
}
The mapping is compiled with mknormattr CORPUS SOURCE_ATTRIBUTE TARGET_ATTRIBUTE. See MAPTO directive documentation.
This configuration can accept multiple values, separated by commas.
Wordcount
This attribute has been sunset and is no longer used.
The structure attribute “wordcount” represents the number of words in a structure. The value is calculated during compilation, the attribute should not be present in the vertical file.
STRUCTURE doc {
ATTRIBUTE wordcount
}
Data representation options
The following lists attributes and structure types that can be used to modify how the index is built or accessed at runtime. To place them in the configuration file, modify the STRUCTURE or ATTRIBUTE as follows:
ATTRIBUTE/STRUCTURE {
TYPE ""
}
e.g.
ATTRIBUTE word {
TYPE "FD_FGD"
}
Attribute types
The names follow the pattern “_” where specifies handling of the .rev index file and specifies handling of the .text index file. The lexicon (.lex) is always memory mapped. If or starts with “M”, it denotes memory mapping, with “F” it denotes file based access without memory mapping. Generally switching between types that differ only in the M/F letters does not require recompilation, switching between any other types always requires recompilation of the corpus.
Positional attributes
MD_MD (default for positional attributes)
Both .rev and .text file use the delta-code index and are memory mapped. Cannot be used for .text files exceeding 500 MB.
FD_MD
As above but the .rev file is not memory mapped while the .text file is.
[since manatee 2.159.5] Same as MD_MD.
FD_FD
As above but neither the .rev nor the .text index is memory mapped.
[since manatee 2.159.5] Same as MD_MD.
FFD_FD
As above plus the .rev.idx index is not memory mapped too.
[since manatee 2.159.5] Same as MD_MD.
FD_FBD
As FD_FGD below but maximally for a few billion tokens. It has already been replaced with the FD_FGD attribute which is highly recommended to use instead of this attribute. The .rev and .text files are memory mapped.
[since manatee 2.159.5] The .rev and .text files are memory mapped.
MD_MGD
Type of an attribute which should be used for any corpora with the main binary file (.text) bigger than 500MB (approx 250M tokens, depending on lexicon size). The .rev and the .text index files are memory mapped, the latter one uses giga delta-codes.
FD_FGD
As above except .rev and .text are not memory mapped.
[since manatee 2.159.5] Same as MD_MGD.
NoMem
As above but all .rev, .rev.idx, .text and .text.off indices are not memory mapped. In addition, any statistic indices are not memory mapped too.
[since manatee 2.159.5] Same as MD_MGD.
Structure attributes
MD_MI (default for structure attributes)
Both .rev and .text files are memory mapped, but the latter one uses plain integers instead of delta-codes.
FD_MI
As above but the .rev index is not memory mapped.
[since manatee 2.159.5] Same as MD_MI.
UNIQUE
Type of an attribute which can be used if the attribute values are unique. The compilation of such an attribute is much faster then and the indices require less space (no reverse index (.rev.*) and .text.* needed)
Structures
Switching among the default (not given) type, file32 and map32 or among file64 and map64 does not require recompilation, any other switching of types requires recompilation of the corpus.
(default)
The .rng file is not memory mapped and cached. Supports corpora up to 231 positions.
[since manatee 2.181.4] The .rng file is memory mapped.
file32
As above but the .rng file is not memory mapped but cached.
[since manatee 2.181.4] The .rng file is memory mapped.
map32
As above but the .rng file is memory mapped.
file64
Enables the range file (.rng) to address 263 corpus positions. It is necessary to use when there are more than 231 tokens in the corpus. The .rng file is not memory mapped but cached.
[since manatee 2.181.4] The .rng file is memory mapped.
map64
As above but the .rng file is memory mapped. Do not use when the range file is too large so as not to allocate too much system resources (.rng must fit into the system memory).ftr
