heTenTen: Hebrew Corpus from the Web
The Hebrew Web Corpus (heTenTen) is a Hebrew corpus made up of texts collected from the Internet. The corpus belongs to the TenTen corpus family which is a set of the web corpora built using the same method with a target size 10+ billion words. Sketch Engine currently provides access to TenTen corpora in more than 30 languages.
Data was crawled by the SpiderLing web spider in November and December 2019, November and December 2020, and January 2021. The whole Hebrew Web corpus is comprised of more than 2.7 billion words from 43,000+ web domains. The Hebrew corpus 2021 (heTenTen) was processed by Yet Another (natural language) Parser.
Detailed information about TenTen corpora is on the separate page Common TenTen corpora attributes.
Overview of Hebrew corpora (heTenTen)
Sketch Engine provides access to a few Hebrew corpora from the web:
- Hebrew Web 2021 (heTenTen21, processed by Yet Another (natural language) Parser) – 2.7 billion words, part-of-speech tags available
- Hebrew Web 2014 (heTenTen14) – 890 million words, without part-of-speech tags
- Hebrew Web 2014 (heTenTen14, processed by Meni Adler‘s tool) – 890 million words, part-of-speech tags available, limited to academic use only
Part-of-speech tagsets in Hebrew corpora
The heTenTen Hebrew corpora have two different part-of-speech tagsets available.
- Hebrew Web corpus 2021 (heTenTen21) – part-of-speech tagsets by YAP tool.
- Hebrew Web corpus 2014 (heTenTen14) – part-of-speech tagsets by Meni Adler‘s tool with thanks to Noam Ordan.
Hebrew corpus 2014
Token attributes in Hebrew Web 2014 corpus (version with POS tagging)
Hebrew is a language with a rich morphology. The tagger output in Hebrew has 27 different attributes, some of which are relevant only to certain parts of speech. Apart from usual attributes such as word, tag and lemma, there are transcriptions to latin alphabet, various morphology categories (affixes), various grammatical categories (gender, number, person, case). The tagset reference can be found below.
Whenever an attribute is irrelevant or missing, its value is string ‘NULL’. For example, to search for all nouns in the corpus which are prefixed with the definite article, issue the following CQL query: [tag=”noun” & prefdefinite=”NULL”].
Tokens, lemmas, prefixes and suffixes were transliterated according to the following key:
ת ש ר ק צ פ ע ס נ מ ל כ י ט ח ז ו ה ד ג ב א
a b g d h w z x v i k l m n S y p c q r e T
Whereas the token and lemma attributes are available both in Hebrew alphabet and romanised transliteration, the prefix string and the suffix string appear only in transliteration.
Full name |
Attribute |
Values |
| Word | word | |
| Transliteration of the word | trans | |
| Lemma | lemma | |
| Transliteration of thelemma | transl | |
| Part of speech | tag | adjective, adverb, conjunction, copula, existential, foreign, interjection, interrogative, modal, negation, noun, numberExpression, numeral, participle, preposition, pronoun, properName, punctuation, quantifier, title, url, verb, wPrefix |
| Part of speech type | postype | amount and arithmetic-operation, bracket-end, bracket-start, colon, comma, coordinating, demonstrative, determiner, dot, exclamation-mark, gematria, hyphen, impersonal, literal-number, numeral-cardinal, numeral-fractional, numeral-ordinal or other, partitive, personal, proadverb, prodet, pronoun, question-mark, quote, reflexive, relativizing, semicolon, slash, subordinating, yesno |
| Prefix string | prestring | ב בכ ו וב ובכ וכ וכש וכשל ול ומ ומכ ומש וש ושב ושל ושמ כ ככ כש כשב כשל כשמ ל לכ לכש מ מכ מש משב משכ משל משמ ש שב שכ שכש שכשמ של שמ שמש |
| Base string | basestring | |
| Suffix string | sufstring | גם ה הם הן ו י ך כם כן ם ן נו |
| Gender | gender | feminine, masculine, masculine-and-feminine |
| Number | number | dual, dual-and-plural, plural, singular, singular-and-plural |
| Status | status | absolute, construct |
| Polarity | polarity | negative, positive |
| Person | person | 1, 2, 3, any |
| Tense | tense | beinoni, future, imperative, infinitive, past |
| Binyan | binyan | Hifil, Hitpael, Hufal, Nifal, Paal, Piel, Pual |
| Prefix conjunction | prefconj | conjunction |
| Prefix definite article | prefdefinite | definiteArticle |
| Prefix interrogative | prefinterrog | |
| Prefix preposition | prefprep | preposition |
| Prefix subordination conjunction / relativizer | relativizer | relativizer / subordinatingConjunction |
| Prefix temporal subordinating conjunction | preftemp | temporalSubConj |
| Prefix adverb | prefadv | adverb |
| Suffix function | suffunction | accusative-or-nominative, possessive, pronomial |
| Suffix number | sufnum | plural, singular |
| Suffix gender | sufgender | feminine, masculine, masculine-and-feminine |
| Suffix person | sufper | 1, 2, 3 |
Access policy for Hebrew Web 2014 corpus (version with part-of-speech tagging)
Access to the corpus is only limited to academic use. To gain access, send an email to support@sketchengine.eu with proof of your academic affiliation. This can be
- a link to your personal profile page on the university website
- scanned copy of your certificate of studies
- your student card, ITIC or ISIC card
- an email request sent from your university mailbox.
Tools to work with the Hebrew corpus
A complete set of Sketch Engine tools is available to work with this Hebrew corpus to generate:
- word sketch – Hebrew collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word units
- word lists – lists of Hebrew nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
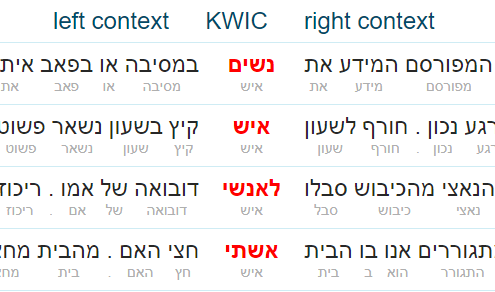
- concordance – examples in context
- text type analysis – statistics of metadata in the corpus
Changelog
heTenTen21 (October 2021)
- 3.1 billion tokens
- part-of-speech tagged and lemmatized by YAP tool
- word sketches in CoNLL format
initial version heTenTen14 (September 2014)
- Crawled by SpiderLing in August 2014
- 1.061 billion tokens
-
version 1 heTenTen14 (January 2015)
- PoS tagged & annotated with morphological categories
Search the Hebrew corpus
Sketch Engine offers a range of tools to work with this Hebrew corpus from the web.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.
