ParlaTalk: automatically updating corpora of parliamentary debates
The ParlaTalk corpora are a set of 22 corpora comprising almost 3 billion words of parliamentary debate transcriptions in 20 languages. The texts were gathered from the parliamentary websites of 22 member states of the European Union. (The missing states do not provide documents in a format suitable for automatic processing.) The ParlaTalk corpora are monitor corpora that are regularly and automatically updated once a month. ParlaTalk corpora grow by about 200 million words in total every year.
The ParlaTalk corpora contain metadata (also called text types) such as the meeting date or speaker’s name. The text types are in a unified format across all corpora. Some corpora include additional text types, e.g. notes of the transcriber or speaker’s party association.
Each ParlaTalk corpus covers a different period depending on the published data of the specific parliament. Usually, it means the last 5 years are included, but sometimes also earlier years are included as well. The most up-to-date documents may not be present if:
- The chamber published the document but marked it as non-final. In this case, it will be downloaded when the final version is published.
- The chamber publishes the documents in batches. Sometimes, this delay takes up to a year.
Part-of-speech tagset, lemmatization
All corpora are part-of-speech tagged, indicating the part of speech and grammatical category, and lemmatized when each word form from the corpus is assigned to its base form (lemma). The particular part-of-speech tagset can be checked within the Sketch Engine interface.
Specifications on processing ParlaTalk Belgium - parliamentary debates
The ParlaTalk Belgium corpus contains texts in two languages: French and Dutch. More specifically:
- Chamber of Representatives (Lower House) – texts in both French and Dutch
- Senate (Upper House) – only in French, since the Dutch texts are direct translations of the French originals
Each language version of the corpus contains the same content but is processed with different tools:
- ParlaTalk Belgium (French) – processed using French-language tools
- ParlaTalk Belgium (Dutch) – processed using Dutch-language tools
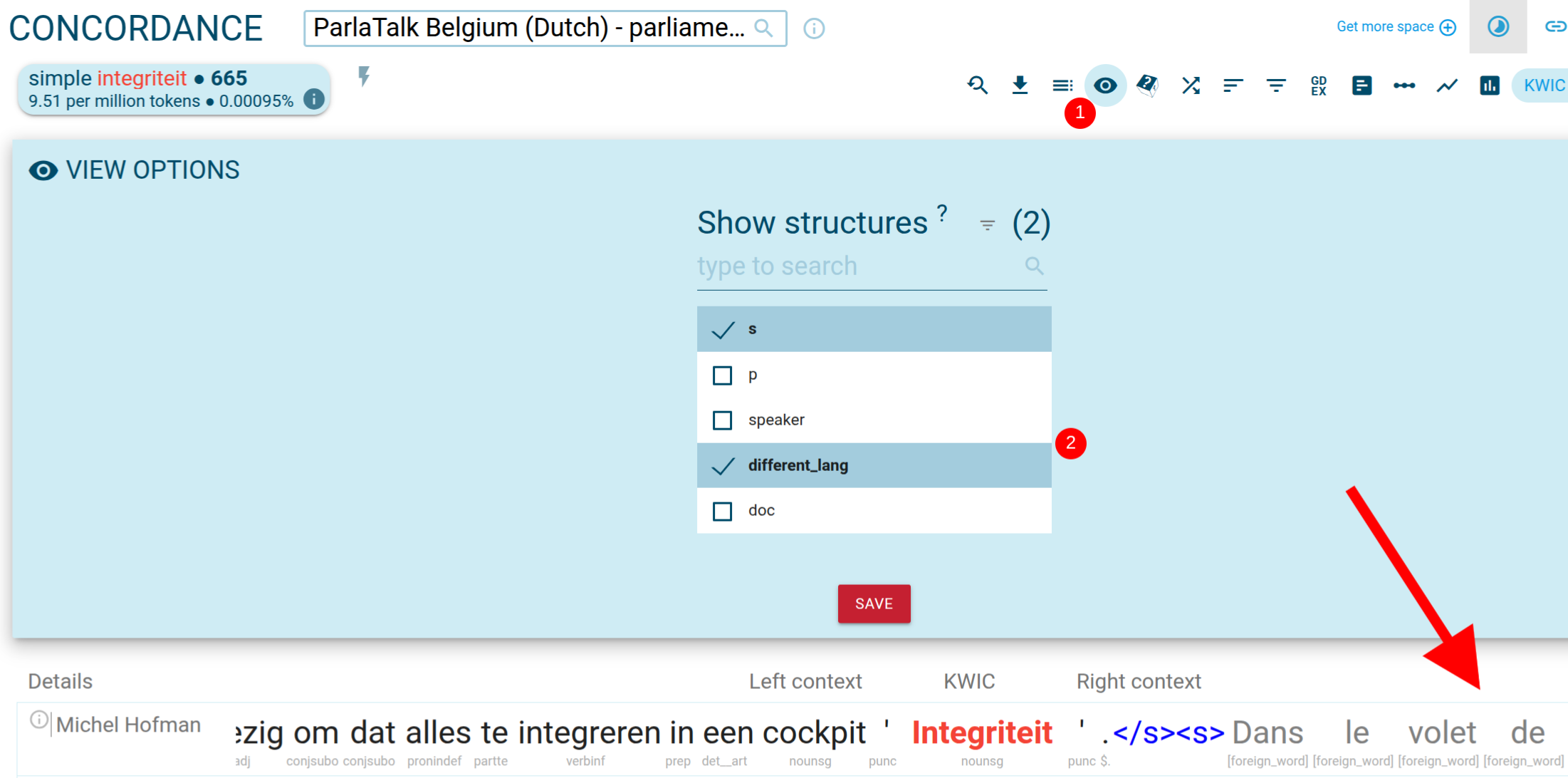
The other language in each corpus (Dutch in the French corpus, or French in the Dutch corpus) is annotated as foreign words. In the concordance results, these foreign words are shown in grey.
To view this display:
- Go to View options.
- Under Show structures, select
different_lang. - Click Save.
ParlaTalk corpora — corpus sizes
The total size of ParlaTalk corpora is 2.8 billion words as of July 2025. The table below shows the corpus sizes of particular national parliaments.
Tools to work with the ParlaTalk corpora
A complete set of Sketch Engine tools is available to work with these corpora of parliamentary debates to generate:
- word sketch – collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word and multi-word units
- word lists – lists of nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- trends – diachronic analysis automatically identifies neologisms and changes in use
- text type analysis – statistics of metadata in the corpus
Bibliography
Use this paper to cite the ParlaTalk corpora:
- MIKUŠEK, Ota. One Year of Continuous and Automatic Data Gathering from Parliaments of European Union Member States. Online. In Darja Fišer, Maria Eskevich, David Bordon. Proceedings of the IV Workshop on Creating, Analysing, and Increasing Accessibility of Parliamentary Corpora (ParlaCLARIN) @ LREC-COLING 2024. Torino, Italia: ELRA Language Resource Association, 2024, p. 149-153. ISBN 978-2-493814-24-1.
For more information, you may refer to:
- MIKUŠEK, Ota. Data Gathered with Automatic Tools from European Parliamentary Chambers. In A. Horák, P. Rychlý, A. Rambousek (eds.). Recent Advances in Slavonic Natural Language Processing, RASLAN 2023. Brno, Czech Republic: Tribun EU, 2023, p. 107-112. ISBN 978-80-263-1793-7.
- MIKUŠEK, Ota. Continuous automatic development of European parliamentary corpora. Online. Bachelor’s thesis. Brno: Masaryk University, Faculty of Informatics. 2023. Available from: https://is.muni.cz/th/ub78x/.
ParlaTalk corpora
A set of 22 corpora of parliamentary debates in 20 languages, automatically updated once a month.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms. Use our Quick Start Guide to learn it in minutes.
