ruTenTen: Corpus of the Russian Web
The Russian Web Corpus (ruTenTen) is a Russian corpus made up of texts collected from the Internet. The corpus belongs to the TenTen corpus family which is a set of the web corpora built using the same method with a target size 10+ billion words. Sketch Engine currently provides access to TenTen corpora in more than 50 languages. The corpora are built using technology specialized in collecting only linguistically valuable web content.
The Russian Web corpus 2020 is cleaned, deduplicated and cleaned of Ukranian and Belarusian texts. It is processed with the RFTagger and TreeTagger tool.
It contains POS tags, lemmas, lempos and word sketches enabling to explore the grammatical and collational behavior of the Russian language. The sample texts of the largest web domains which account for 36% of all corpus texts were checked manually and content with poor quality text and spam was removed.
Detailed information about TenTen corpora is on the separate page Common TenTen corpora attributes.
Part-of-speech tagset
The summary of POS tags used in these Russian corpora is here.
Overview of Russian TenTen corpora
This is a list of Russian Web corpora available in Sketch Engine:
- Russian Web corpus 2020 (ruTenTen20) – 19 billion words, genre annotation and topic classification
- Russian Web corpus 2017 (ruTenTen17) – 9 billion words
- Russian Web corpus 2011 (ruTenTen11) – 14.5 billion words
Russian Web 2020 corpus sizes
| Frequency | |
| Tokens | 23+ billion |
| Words | 19+ billion |
| Sentences | 1+ billion |
| Web pages | 40+ million |
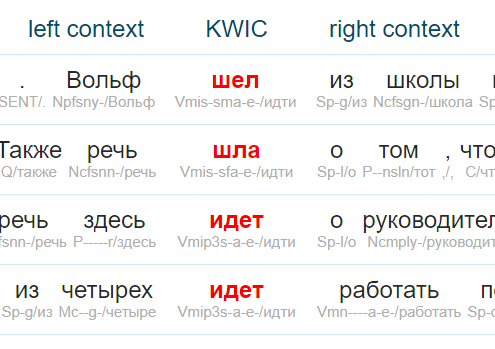
Search the Russian Corpus
Sketch Engine offers a range of tools to work with this Russian Corpus
Genre annotation and topic classification
A part of the Russian Web 2020 corpus contains genre annotation and topic classification. These can be displayed as corpus structures in Concordance or in the Text type Analysis tool. Genres refer to writing styles and are divided into four groups (blog, discussion, fiction, legal, news, reference/encyclopedia) whereas topic classification is inspired by categories used by https://curlie.org/ (formerly dmoz.org) and includes the following topics: arts, beauty & fashion, cars & bikes, culture & entertainment, economy finance & business, games, health, history, hobbies, home family & children, nature & environment, pets & animal, politics & government, religion, science, sex, sports, technology & IT, and travel & tourism.
- genres cover 5.78% of the corpus, i.e. 1.3 billion tokens
- topic classification covers 2% of the corpus, i.e. 460 million tokens
Please refer to our article on topic and genre classification for more information: https://www.sketchengine.eu/blog/topics-and-genres-in-corpora/
Hover over the chart to display a number of tokens of the particular topic.
Tools to work with the Russian Web Corpus
A complete set of Sketch Engine tools is available to work with the Russian corpus to generate:
- word sketch – Russian collocations categorized by grammatical relations
- thesaurus – synonyms and similar words for every word
- keywords – terminology extraction of one-word and multi-word units
- word lists – lists of Russian nouns, verbs, adjectives etc. organized by frequency
- n-grams – frequency list of multi-word units
- concordance – examples in context
- text type analysis – statistics of metadata in the corpus
Changelog
rutenten20_rft3 (March 2025)
- bad content removal
- partial topic and genre classification
version 8 (November 2014)
- further cleaning of Ukrainian and Belarusian texts
- dynamic case, number, gender
- gender lemma attribute
version 7 (April-May 2014)
- reprocessed with the RFTagger and TreeTagger tool – 14.5 billion words
- removed documents containing Ukrainian characters [ІіЇїЄє] or Belarusian characters [Ўў],
- removed documents from sites yielding high relative frequency of word порно (porn)
- added lempos
version 1 (April 2012)
- initial version – 15.8 billion words
Bibliography
TenTen corpora
SUCHOMEL, Vít. Better Web Corpora For Corpus Linguistics And NLP. 2020. Available also from: https://is.muni.cz/th/u4rmz/. Doctoral thesis. Masaryk University, Faculty of Informatics, Brno. Supervised by Pavel RYCHLÝ.
Jakubíček, M., Kilgarriff, A., Kovář, V., Rychlý, P., & Suchomel, V. (2013, July). The TenTen corpus family. In 7th International Corpus Linguistics Conference CL (pp. 125-127).
Suchomel, V., & Pomikálek, J. (2012). Efficient web crawling for large text corpora. In Proceedings of the seventh Web as Corpus Workshop (WAC7) (pp. 39-43).
Genre annotation
SUCHOMEL, Vít. Genre Annotation of Web Corpora: Scheme and Issues. In Kohei Arai, Supriya Kapoor, Rahul Bhatia. Proceedings of the Future Technologies Conference (FTC) 2020, Volume 1. Vancouver, Canada: Springer Nature Switzerland AG, 2021. s. 738-754. ISBN 978-3-030-63127-7. doi:10.1007/978-3-030-63128-4_55.
Use Sketch Engine in minutes
Generate collocations, frequency lists, examples in contexts, n-grams or extract terms is easy. Use our Quick Start Guide to learn it in minutes.
