
- ALDF – Average Logarithmic Distance Frequencyis a modified frequency that prevents the result from being excessively influenced by one part of the corpus (e.g. one or more documents) that contain a high concentration of the token. If the token is evenly distributed across the corpus, ALDF and absolute frequency will be similar or [...] Read More
- alignmentAlignment is a term used in connection with parallel corpora. A parallel corpus consists of a text and its translation into one or more languages. Parallel corpora need to be divided into segments. A segment usually corresponds to a sentence. Alignment refers to information that tells Sketch [...] Read More
- ARF – Average Reduced Frequencya modified frequency which prevents the result to be excessively influenced by one part of the corpus (e.g. one or more documents) which contains a high concentration of the token. If the token is evenly distributed across the corpus, ARF and absolute frequency will be similar or identical. [...] Read More
- AttributeAn attribute can refer to:
- A positional attribute - information added to each token in a corpus, e.g. its lemma or part of speech. more»
- A structure attribute - information added to a structure in a corpus, often called metadata
- CAT toolA CAT tool is a computer-assisted translation tool. It is software that helps translators maintain consistency in terminology across their translation projects and also aids the translation process by suggesting (or automatically translating) passages (segments) that have already been [...] Read More
- clusterClustering is the process of creating groups of words in the thesaurus or word sketch. Words are connected by their shared collocational behaviour. See more on the Clustering Neighbours documentation
- collocateis the part of a collocation that is not the node. A collocate is dependent on the node.
The collocate strong and the node wind make up the collocation strong wind
The most typical [...] Read Morecollocation collocate node strong wind icy wind cold wind - collocationA collocation is a sequence or combination of words that occur together more often than would be expected by chance (from Wikipedia|Collocation) A collocation, e.g. fatal error, typically consists of a node (error) and a collocate (fatal). !--more--The words in a collocation may appear [...] Read More
- comparable corpusA comparable corpus is a corpus consisting of texts from the same domain in more languages. In contrast to a parallel corpus, the texts are not translations of each other and belong to the same domain with the same metadata. An example of a comparable corpus is corpus made from Wikipedia.
- compileA corpus compilation refers to the processing of the corpus data (text) with the tools available for the language and converting the text into a corpus. Only a compiled corpus can be searched. see corpus compilation
- concordanceis a list of all examples of the search word or phrase found in a corpus, usually in the format of a KWIC concordance with the search word highlighted in the centre of the screen and some context to the right and to the left see also KWIC
- concordancerA concordancer is a tool (a piece of software) which searches a text corpus and displays a concordance. A concordancer is one of the features in Sketch Engine which allows for simple corpus searches as well as queries involving complex criteria that search for grammatical or lexical [...] Read More
- CoNLL formatCoNLL format is a specific format of the vertical file that represents a syntactic parse tree. In comparison with the vertical, there are extra columns describing the syntactic structure of words within the sentence, i.e. id, head, deprel. The number and position of these extra columns may [...] Read More
- cooccurrenceCooccurrence or co-occurrence is a term which expresses how often two terms from a corpus occur alongside each other in a certain order. It usually indicates words which together create a new meaning. We call them phraseme or multi-word expression, e.g. black sheep or get on. Sketch Engine [...] Read More
- corpusA corpus is a large collection of authentic texts used for studying language or generating linguistic data. Modern corpora contain texts whose total length is billions or dozens of billions of words. A corpus is usually tagged. (= annotated, i.e. the words are labelled with information about [...] Read More
- corpus architectis an intuitive tool inside Sketch Engine for creating corpora from documents or the Web which does not require any expert knowledge. See the create your own corpus page.
- corpus manageris a program used to manage text corpora, i.e. to build, edit, annotate and search corpora. Sketch Engine is the user interface to the corpus manager Manatee.
- CQLThe Corpus Query Language is a code used to set criteria for complex searches which cannot be carried out using the standard user interface controls. The criteria may include words or lemmas but also tags and other attributes, text types or structures. Conditions can be set for optional Read More
- CSVis a type of plain text document used for saving tabular data. It is seamlessly accepted by a large variety of applications and is therefore ideal for exporting Sketch Engine results to be used in other software. CSV can be opened directly in Microsoft Excel, Open Office, Google Documents and [...] Read More
- deduplicationDeduplication is a process of removing duplicated content from a corpus. Only the first instance of the text is preserved, any subsequent (duplicated) occurrences are removed. Deduplication is especially important with corpora built by crawling the web. This is because lots of web content [...] Read More
- disambiguationis the process of identifying meanings of words (lemma, part of speech) when a word has multiple meanings. The result of this process is one word with one meaning.
- distributional thesaurusis an automatically produced thesaurus which identifies words that occur in similar contexts as the target word. It draws on the theory of distributional semantics. It is available for every word in the corpus. more about automatic thesaurus The distributional thesaurus in Sketch Engine [...] Read More
- documentA document (called a file in old corpora) in Sketch Engine refers to any file, document or webpage that makes up the corpus. If a user uploads a file (such as .doc, .pdf, .txt), each of the files becomes a corpus document. If the user downloads content from the web, each web page becomes a [...] Read More
- document frequency (docf)Document frequency is the number of documents in which a token or phrase appears. If the corpus has 100 documents and 2 documents contain the word city: document number 7 contains 17 instances of city, document number 31 contains 6 instances of city, the document frequency of city is [...] Read More
- escapingIn regular expressions, escaping refers to canceling the special function of certain characters, typically when searching for punctuation.
These characters must be excaped if you want to search for the character:
. ^ $ * + ? ( ) [ ] { } | \In CQL, also the double quotes"must be [...] Read More - focus corpusIn keyword and term extraction, the focus corpus is the corpus from which keywords and terms are extracted. Compare reference corpus.
- relative frequency, frequency per million(also called freq/mill in the interface) is the number of occurrences of an item per million tokens, also called i.p.m. (instances per million). It is used to compare frequencies between corpora (or datasets) of different sizes.
Formula
number of hits : corpus size in millions of tokens = [...] Read More - frequencyFrequency (also absolute frequency) refers to the number of occurrences or hits. If a word, phrase, tag etc. has a frequency of 10, it means it was found 10 times or it exists 10 times. It is an absolute figure. It is not calculated using a specific formula. compare frequency per [...] Read More
- GDEXGood Dictionary Examples is a technology in Sketch Engine which can identify automatically sentences which are suitable as dictionary example sentences or as teaching examples, i.e. are illustrative and representative. The GDEX can be applied to any concordance. It will sort the lines and [...] Read More
- gender lemmaThe gender lemma is an attribute used in connection with term extraction. Its purpose is to display terminology in the correct word form in languages which observe the agreement in gender between adjectives and nouns. The standard lemma would produce a grammatically unacceptable word form [...] Read More
- global subcorpusA subcorpus that is shared with all users. See instructions how to set the subcorpus shared all users»
- glue
A glue is a special structure inserted into a corpus to tell Sketch Engine that two tokens, which would otherwise be displayed with a space in between, should actually be displayed without a space. Typically do and n't will have glue between them to be displayed as don't. A glue does not [...] Read More - Grammatical relationA grammatical relation, or gramrel, refers to one column in the word sketch. Each column represents a category which displays collocates with the same relation to the search word, e.g. subjects of a verb or modifiers of a noun. Some columns may also display the usage statistics of the search [...] Read More
- header fieldVarious types of information associated with documents of a corpus, e.g. a corpus with documents from different domains can be structured according to these domains with a usage of header fields
and their values "nameofdomain" = Read More - keyword(Not to be confused with terms which is a related concept.) Keywords are a concept used in connection with Keyword & Term extraction. Keywords are words (single-token items), that appear more frequently in the focus corpus than in the reference corpus. They are used to identify what is [...] Read More
- KWICKWIC is the acronym for Key Word in Context and refers to the red text highlighted in a concordance. The red text is the result that matches the search criteria. Such a concordance is referred to as a KWIC concordance. !--more--The KWIC concordance is the preferred format for displaying [...] Read More
- lc (also referred to as word_lc, word lowercase or word form lowercase) is a positional attribute assigned to each token in the corpus. It contains the lowercase variant of the word attribute: John becomes john, Apple becomes apple, BE becomes be. The lc [...] Read More
- learner corpusA collection of texts produced by learners of a language used to study errors and mistakes made by learners of languages. Learner corpora in Sketch Engine can use both error and correction annotation. A special search interface is available to search by the former or the latter or both. see [...] Read More
- lemma Lemma is a positional attribute. It is the basic form of a word, typically the form found in dictionaries. A lemmatized corpus allows for searching for the basic form and include all forms of the word in the result, e.g. searching for lemma go will find go, [...] Read More
- lemma_lc lemma_lc is a positional attribute. It is a lemma converted to lowercase. apple and Apple are treated as the same thing. It is used for case insensitive searching and case insensitive analysis. see lemma
- LemmatizationLemmatization is a process of assigning a lemma to each word form in a corpus using an automatic tool called a lemmatizer. Lemmatization bring the benefit of searching for a base form of a word and getting all the derived forms in the result, e.g. searching for go will also find goes, went, [...] Read More
- lempos Lempos is a positional attribute, i.e. an attribute assigned to each token in the corpus. It is a combination of lemma and part of speech (pos) consisting of the lemma, hyphen and a one-letter abbreviation of the part of speech, eg. go-v, house-n. The [...] Read More
- lempos_lc lempos_lc is a positional attribute. It is a lowercased version of lempos. All uppercase letters are converted to lowercase, thus House-n becomes identical with house-n. It is used for case insensitive searching and analysis. see also lempos list [...] Read More
- likelihoodis a function of parameters of a statistical model. It plays a key role in statistical inference and is the basis for the log-likelihood function. see Statistics in Sketch Engine
- log-likelihoodis one of the functions used in the computed statistics of Sketch Engine. It is an association measures based on the likelihood function and is used in tests of significance (see the log-likelihood calculator and more details).
- logDiceis a statistical measure for identifying co-occurrence (=two items appearing together). Sketch Engine uses it to identify collocations. It expresses the typicality (or strength) of the collocation. It is used in the word sketch feature and also when computing collocations from a [...] Read More
- longest-commonest matchThe longest-commonest match (LCM) was coined by Adam Kilgarriff to name the most common realisation of a collocation, i.e. the chunk of language in which the collocation appears most frequently. The longest-commonest match is part of the word sketch result screen to facilitate the [...] Read More
- longtagLongtag is a detailed part-of-speech tag that usually contains more information than a tag. Some corpora use tags that contain only basic part-of-speech information, while attribute longtags consist of more detailed grammatical information such as case, number, gender, etc. The longtags [...] Read More
- macroMacro is a concordance feature that automates your usual concordance operations. Macros let you save all the actions applied on the concordance and carry them out automatically on future concordances.
- metadataare information about the texts in the corpus: for example, year of publication, author name, publishing house, medium (written, spoken), register (formal, informal) etc. Metadata are automatically converted to text types in Sketch Engine. see Annotate a corpus Read More
- MI ScoreThe Mutual Information score expresses the extent to which words co-occur compared to the number of times they appear separately. MI Score is affected strongly by the frequency, low-frequency words tend to reach a high MI score which may be misleading. !--more--This is why Sketch Engine [...] Read More
- minimum sensitivity
A statistics measure similar to logDice which is the minimum of the two following numbers:
- the number of co-occurrences divided by the frequency of the collocate
- the number of co-occurrences divided by the frequency of the node word
The minimum sensitivity number grows with a [...]
Read More - multilevel listis a list sorted at more than one level, e.g., a frequency list sorted by word form followed by lemma and then tag, see this multilevel list in the BAWE corpus.
- n-gramis a sequence of items (bigram = 2 items , trigram = 3 items ...n-gram = n items). An item can refer to anything (letter, digit, syllable, token, word or others) . In the context of corpora and corpus linguistics, n-grams typically refer to tokens (or words). In linguistics, n-grams are [...] Read More
- node(talking about collocations) the central word in a collocation, e.g. strong wind consists of the collocate strong and the node wind (talking about concordances) the search word or phrase, sometimes called a query, that appears in the centre of a KWIC concordance or highlighted in other [...] Read More
- non-wordNon-words (also spelt nonwords) are tokens which do not start with a letter of the alphabet. Examples of non-words are numbers, punctuation but also tokens such as 25-hour, 16-year-old, !mportant, 3D. Tokens such as post-1945, mp3 or CO2 are words because they start with a letter. The [...] Read More
- overall scoreThe score of the relation based on logDice in word sketches. The score is displayed in the header of each column of the relation.
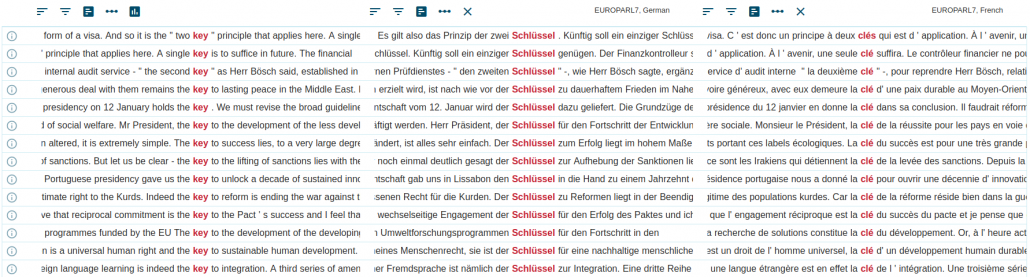
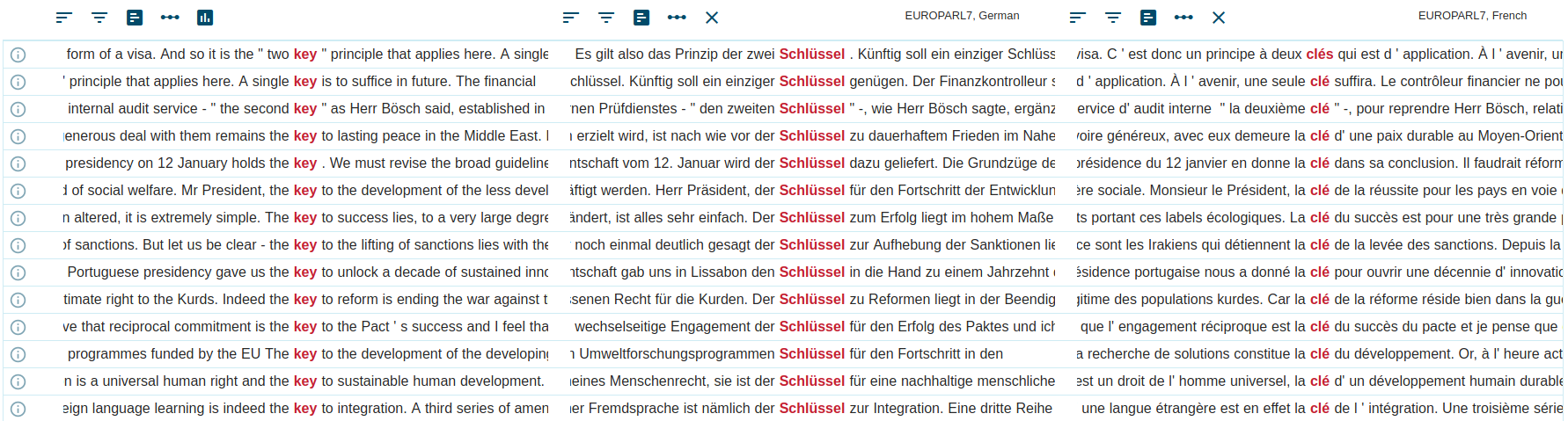
- parallel corpusA parallel corpus consists of the same text translated into one or more languages. The texts are aligned (matching segments, usual sentences, are linked). The corpus allows searches in one or both languages to look up or compare translations.
- POSPOS stands for "part of speech" such as noun, adjective, verb, adverb etc. In Sketch Engine, POS also refers to a positional attribute which is assigned to tokens in the corpus and contains information about the part of speech only. It does not include any additional information. (Do not [...] Read More
- POS tagA POS tag (also part-of-speech tag) is the same as tag. Do not mistake for POS, the simplified POS tag showing only the part-of-speech information but not the additional morphological and grammatical information. See also positional attributes lempos lemma
- POS taggerPOS (part of speech) tagging is a process of annotating each token with a tag carrying information about the part of speech and often also morphological and grammatical information such as number, gender, case, tense etc. The automatic tagging tool is called a tagger or POS tagger. See [...] Read More
- positional attribute
A positional attribute is information added to each token in a corpus, typically its lemma or tag. Attributes differ between languages and, occasionally, even between corpora in the same language. Here are some examples of attributes:
Read Moreword lemma tag - preloaded corpusa ready-to-use corpus included in Sketch Engine subscription or Trial access, not created by a user, e.g. English Trends corpus
- prevertical fileA prevertical file is a plain text file that contains the corpus text and structures. Usually, it is a source file for creating vertical files which are created by the tokenization process from the prevertical.!--more-- An example of a prevertical file with corpus structures for documents, [...] Read More
- querya sequence of characters or words or their combinations inputted by the user in order to retrieve a concordance. Often, the word query is not restricted to the concordance only but can also refer to any type of search or criteria used in connection with any Sketch Engine feature, i.e. Word [...] Read More
- reference corpusA reference corpus is used in keyword extraction and term extraction. A reference corpus is a corpus to which the focus corpus is compared. When using the Keywords & Terms tool, a reference corpus is preselected but the user can use a different corpus as a reference corpora. The reference [...] Read More
- regular expressionsa collection of special symbols that can be used to search for patterns rather than specific characters, e.g. to find all words starting, containing or ending in a specific sequence of characters, for example .*tion will find all words ending in tion and having an unlimited number of [...] Read More
- relative text type frequency(also called Relative density in the interface) Relative text type frequency compares the frequency in a specific text type to the frequency in the whole corpus. It shows how typical the word(s) is of a specific text type, e.g. of the spoken part of the corpus or of a particular website from [...] Read More
- salienceis a statistical measure of the significance of a specific token in a given context. It is measured using logDice. For more information, see section 3 of Statistics used in Sketch Engine.
- search attributeis the attribute used for searching and for creating a word list. Word lists can be created for words, lemmas, tags, etc.
- search spanis the number of tokens on either side of the node that are matched when filtering concordance lines. A search span of −5 to 5 means that all concordance lines containing the filter condition within a range of five tokens around the node are returned.
- segmentSegments refer to the parts into which a parallel (multilingual) corpus is divided for the purpose of alignment. Alignment means that the corpus contains information about which segment in one language is a translation of which segment in another language. Segments typically correspond to [...] Read More
- simple mathsThe simple maths formula is used to calculate the keyness score in Sketch Engine. This score is used to identify terms, keywords and also key n-grams and key collocations. It identifies items which appear more frequently in the focus corpus than in the reference corpus. It uses relative (per [...] Read More
- stemA stem is a part of a word without its affixes (suffixes, prefixes, etc.). Stems do not have to be valid word forms, e.g. stem hav for the word form having, in comparison to lemma have for the word form having. Stems are used instead of lemmas or in addition to lemmas with languages whose [...] Read More
- stemmingstemming is the process during which a word reduces its affixes (suffixes, prefixes, etc.) and finally, the stem only remains. Stemming is used to detect related words with the same stem, the word root which does not change in any case, number or tense. The word stems are available in Read More
- structurea corpus structure refers to the segments or parts into which a corpus can be divided. Typically, a corpus is divided into sentences, paragraphs and documents but the corpus author can introduce various other structures to allow the analysis to focus on smaller or larger parts of the [...] Read More
- subcorpusa corpus can be subdivided into an unlimited number of parts called subcorpora. Subcorpora can be used to divide the corpus by the type (fiction, newspaper), media (spoken, written) or time (e.g. by years) or by any other criteria. A subcorpus can also be created from a concordance by [...] Read More
- T-scoreT-score expresses the certainty with which we can argue that there is an association between the words, i.e. their co-occurrence is not random. The value is affected by the frequency of the whole collocation, which is why very frequent word combinations tend to reach a high T-score despite [...] Read More
- tag(also called part-of-speech tag, POS tag or morphological tag) is a label assigned to each token in an annotated corpus to indicate the part of speech and often also grammatical categories and morphological information. The tool used to annotate a corpus is called a tagger. A collection of [...] Read More
- tagset(called also tag set) is a list of part-of-speech tags used in one corpus. In Sketch Engine, corpora in the same language tend to use the same tagset but exceptions exist. To check the tagset used, access Corpus statistics and details. See our blog about POS tags.
- TBLis an application in Sketch Engine for collecting usage-example sentences to build dictionaries. Find more on the Tick Box Lexicography page
- termTerms is a concept used in connection with Keywords & Terms tool. A term is a multi-word expression (consisting of several tokens) which appears more frequently in one corpus (focus corpus) compared to another corpus (reference corpus) and, at the same time, the expression has a format of [...] Read More
- term baseIn connection with CAT tools, a term base is a database of subject-specific terminology and other lexical items which need to be translated consistently. The CAT tool uses the term base to check the consistency of translation, to look for untranslated segments, and to suggest (or [...] Read More
- term extractionthe process of identifying subject specific vocabulary in a subject specific text usually using specialized software. The identification of one-word and multi-word terms in Sketch Engine is based on the comparison of the frequency of such words and phrases between the reference corpus and the [...] Read More
- term grammarA term grammar is a set of rules written in CQL which define the lexical structures, typically noun phrases, which should be included in term extraction. The lexical structures are defined using POS tags and CQL. The use of a term grammar ensures a clean term extraction result which requires [...] Read More
- text analysisText analysis (also content analysis or text analytics) is a method for analyzing (usually unstructured) text in order to extract information. The result of the text analysis is structured data. In addition to the traditional tools, Sketch Engine also offers some unique features. The [...] Read More
- text miningText mining is an automatic process of extracting information from text, such as keywords of a text or its source(s). The corresponding tools in Sketch Engine are WebBootCaT for creating corpora from the web or keywords and terms extraction tool, which finds terminology in your texts. See [...] Read More
- text type[We follow Biber (1989) in using text type as a generic term for the many ways in which a text might be classified.] A text type refers to values assigned to structures (e.g. documents, paragraphs, sentences or others) inside a corpus. Text types can refer to the source (newspaper, book, [...] Read More
- text type selectorAny search in Sketch Engine can be limited to certain text types only. The results will be taken from documents annotated with the specific text type(s). Users can include metadata in their corpora. If the metadata are in the required format, they will be converted to text types and will [...] Read More
- timelineThe timeline function displays the changing frequency of a word or phrase over time. Timelines are not a standalone tool, they are included in the Concordance and Wordlist tools. Timelines are computed the same as the graphs in Trends – a diachronic analysis of word usage, however, they can [...] Read More
- TMX - Translation Memory eXchange formatTranslation Memory eXchange (TMX) is a specific XML format used for creating parallel corpora in Sketch Engine. This format is standardly used in translation memories (TM). See more about Setting up parallel corpora in Sketch Engine. An example of a TMX document (from Wikipedia), the [...] Read More
- token
Read More - tokenizationFor the corpus to work, the corpus text should be first divided into individual tokens. Tokenization is the automatic process of dividing text into tokens. This process is performed by tools called tokenizers.
- tokenizerA tokenizer is a tool (software) used for dividing text into tokens. A tokenizer is language specific and takes into account the peculiarities of the language, e.g. don't in English is tokenized as two tokens.!--more-- Sketch Engine contains tokenisers for many languages and also a [...] Read More
- translation memoryA translation memory is a database inside a CAT tool which holds segments of text translated in the past. The CAT tool can suggest (or automatically supply) translations based on matching text from the translation memory.
- trendsTrends is a feature used for diachronic analysis, i.e. for identifying how the frequency of the word (or other attributes) changes over time. read more
- Type/token ratio (TTR)The type/token ratio, often shortened TTR, is a simple measure of lexical diversity. It can only be interpreted when comparing it to TTR of a different text (corpus). The corpus with a higher TTR contains a higher variety of words than the other corpus. In other words, the authors use more [...] Read More
- UMSA feature available to users with local installations for administering users and corpora.
- user corpusa corpus created by a user. Users can create corpora by uploading their own data or using Sketch Engine to collect data from the Web. User corpora are created as private. No other user can access them. However, users can grant access to the corpus to individually selected users. This is [...] Read More
- vertical fileA vertical file is a text file where each token (or word) is on a separate line. This format is typically used for text corpora and may contain additional metainformation (annotation). Vertical files are usually created from a prevertical format.!--more-- The first column contains tokens [...] Read More
- web miningweb mining is the application of data mining which extracts information from texts. The web mining is focused on gaining information and metadata from the web. For this task, Sketch Engine uses the fully-automated tool WebBootCaT for creating corpora from the web which stores also metadata of [...] Read More
- wordNote: This entry is for the type of token. For the positional attribute, see word form. A word is a type of token. All tokens in a corpus are divided into two groups: words and nonwords. Words are tokens which begin with a letter of the alphabet. Tokens such as book, working, Mary, [...] Read More
- word formⓘ This entry is for the positional attribute: word form, lemma, lowercase, tag… For the type of token, the opposite of nonword, see word. The word form (often shortened to word in the interface) is a positional attribute. It refers to one of the word forms [...] Read More
- word listA word list is a generic name for various types of lists such as lists of words, lemmas, POS tags or other attributes with their frequency (hit counts, document counts or others). See more about the wordlist function in Sketch Engine.
- word sketchThe word sketch is a tool to display collocations (=word combinations) in a compact, easy-to-understand way. The word sketch makes it easy to understand how a word behaves, which contexts it typically appears in and which words it can be used with. The word sketch can typically display [...] Read More
- word sketch grammarWord Sketch grammar (WSG) is a set of rules defining the grammatical relations (=columns/categories) in a Word Sketch. In other words, WSG tells Sketch Engine which words should be regarded as collocations of the search word and also what type of collocation they are. WSG defines the [...] Read More
- word sketch tripleA word sketch triple is a data format used for representing one collocation identified by the word sketch. A word sketch triple consists of:
- node as lempos
- name of the grammatical relation as displayed in the header of the column in word sketch interface
- collocate as [...]
Read More
for learners of languages
A Course in Lexicography and Lexical Computing
term extraction
